



 CC-BY 4.0
CC-BY 4.0
1. Introduction
Biology embodies two very different conceptions of what life is. In its most commonly understood form, it exploits what we know of chemistry. On the other hand, under the name of genetics, it conjures up an abstract world, more difficult for most people to grasp, that of the rules of heredity. Either one of these approaches, biochemistry or genetics, provides a conceptual and experimental framework for validating, or not, the hypotheses that seek to explain what life is. The consensus—usually not made explicit—is that for a biological demonstration to be acceptable, it must involve an analytical approach using biochemical experiments in which all the elements are identified and understood. For more than half a century, this consensus has been illustrated by the development of a new field of life sciences, molecular biology, which implies that a purely genetic demonstration—where the modification of a hereditary trait within an organism is used to establish proof of what is sought to be shown—is not accepted as sufficiently convincing by the majority of experimenters. It is in this context that a new discipline, synthetic biology, has emerged. The underlying idea is to transpose to the entire living organism the necessary requirement of a biochemical demonstration, by going beyond the simple analytical method. To do this, it would be sufficient to combine the two entities that define the living cell, defined by its biochemical characteristics, namely a nucleic acid that plays the role of the genetic program and a “chassis” made up of all the machinery that enables this program to be expressed within a semi-permeable envelope that allows the cell to interact with its environment, into a functional whole.
Because of the spectacular successes of molecular biology and the central role played by nucleic acids, most researchers have limited their vision of synthetic biology to the design and synthesis of nucleic acids or analogues acting as genetic programs. This restrictive view is based on the generalization of transfer by conjugation of chromosome pieces, and even whole chromosomes from one species to another, known since the beginnings of molecular biology [1]. Since the late 2000s, we have been able to construct and transplant synthetic genes or genomes directly into model cells [2]. This experimental subset accounts for the vast majority of experiments labeled as synthetic biology. This is where the construction of entities for malicious use is most critical.
To date, the majority of efforts to design chassis for synthetic biology have been focused on simplifying the genome of existing species to make them compatible with the implementation of synthetic genetic networks (see for example [3, 4, 5, 6]). However, focusing solely on the genetic program and its artificial synthesis ignores that, within the cellular chassis, ubiquitous agents that cause the apparent “animation” of biological chemistry make a central contribution, resulting in highly variable outcomes [7]. This is understood by only a very small minority of investigators. The scientific and technical challenges involved in synthesizing a functional chassis de novo are such that only a few laboratories have attempted to achieve this feat [8], and they are still a long way from succeeding. This is mainly due to the fact that it is not enough to assemble all the known components of a model chassis to make it functional [9]. Fortunately, an analysis of the properties required for this creation shows that this domain is ill-suited to a use that can be controlled by malicious operators. We will therefore limit our discussion to gene and genome synthesis, which is a particularly worrying area when considering possibly harmful applications.
2. What synthetic biology is
Unfortunately, fashion often dominates the onset of research trends. In order to have a reasonable chance of developing work, which is always expensive, we have to act like advertising agencies and show that we are part of a vibrant trend. This pervasive constraint, which has replaced the curiosity that was once at the root of the most important discoveries, leads us to use terms that attract funders. “Synthetic biology” is one such term. To understand what is covered by the field, we need to understand what naming means.
2.1. Naming is not without consequences
Umberto Eco underlined this in his book The Name of the Rose: we are nominalists, and for us, the essence of a thing lies in the purity of its name: Stat rosa pristina nomine, nomina nuda tenemus. This is not without consequences, as naming directs our thinking towards a whole context, that of the use of the name in question. The true advocates of the scientific approach are well aware of this, and use Greek roots to name what belongs to science [10], reminding us all of its origins. However, the discipline we call synthetic biology encompasses two distinct fields, each of which involves practices covering both academic expertise and the applications of this knowledge. These practices involve creating processes that are either,
- unnatural with natural components (in this case, it is simply an extension of genetic engineering, which explains why, for many people, synthetic biology is not at all original);
or,
- natural with unnatural components.
This dichotomy vanishes when these processes are combined into heterogeneous assemblies. This obscures the image of synthetic biology, which then evolves in parallel with a very blurred field, that of “systems biology”. This situation amplifies the ambiguity of the term “system”, which is widely used by those who make immoderate use of the term “complex”, meaning both “so complicated that it is impossible to understand” and “which implies a particularly elaborate and therefore mysterious order”. The physicist Murray Gell-Mann tried to remedy this deleterious ambiguity by replacing the Latin “complex” with the Greek “plectics” to avoid the confusion caused by overuse of the term [11]. In a parallel effort Victor de Lorenzo and I attempted to bring the two fields together under the name of “symplectic biology”. We had no better success than Gell-Mann’s attempt, whose article, curiously, did not appear online until long after it had been written, just as we were advancing the same idea [12]. This point of history underscores the ambivalence that affects all discussions questioning the uses, good or bad, of synthetic biology.
2.2. A brief history of the domain
What is fashionable today is the result of a sometimes ancient history that is often ignored by fashion designers or users. Ignorance, which is becoming increasingly widespread, leads us not only to reinvent the wheel, but also, because we have lost our memory, to construct fashions based on the accretion of mutually incompatible entities. This conceptual flaw makes the consequences of the development of synthetic biology, whether good or bad, not only difficult to assess, but also difficult to control properly.
Because it is the title of a work that was quite successful in its day, reference is sometimes made to the book by Leduc (1853–1939), La Biologie Synthétique, published in 1912 [13], to introduce this new field. Its content deserves to be analyzed in depth, as it provides a remarkable illustration of the abusive use of analogy, which is very much in fashion, particularly when it comes to the analogy of forms. What is presented as new today was, in fact, already explicit in 1970 in a commentary by Danielli (1911–1984) [14], detailed in a journal concerned with the negative consequences of the applications of science, the Bulletin of the Atomic Scientists [15]:
We can now readily discern three ages in the science of modern biology: Age of Observation ∼ Age of Analysis ∼ Age of Synthesis. […] The age of synthesis is in its infancy, but is clearly discernable. In the last decade (1960–70), we have seen the first syntheses of a protein, a gene, a virus, a cell, and of allophenic mice. Nothing with such dramatic implications has ever been seen in biology before. Previously, plant and animal breeders have been able to create what are virtually new species, and have been able to do so at a rate which is of the order of 104 times that of average evolutionary processes. A further increase in rate is now on the horizon. We need a few additional “firsts” before this will occur: (1) to be able to synthesize a chromosome from genes and other appropriate macromolecules; (2) to be able to insert a chromosome into a cell; or, alternatively to (1) and (2), to be able (3) to insert genes into a cell in some other way; (4) we must also learn how to bring the set of genes, which is introduced into a cell, within the domain of cellular control mechanisms, so that they do not run wild in the cell. None of these problems appear to be of exceptional difficulty.
In this 1972 article, Danielli warns us, as we do again half a century later:
As this evolution takes place, it may well become necessary to ensure that such organisms cannot live outside their particular required industrial environment, and even include self-destruct mechanisms to reduce their viability in the natural biosphere. However, self-destruct mechanisms, and all other mechanisms which are pathogenic to one species, can only be introduced after the most rigorous theoretical and experimental study because of the possibility, always present with genetic systems, that the pathogenic process may pass from species to species and so generate new fulminating pathogens.
Shortly afterwards, in 1974, the English name “synthetic biology” was proposed by Szybalski [16], to define what was to become genetic engineering, based on the recent access to experimental determination of the sequence of genes. But, as a result of this fashion that ignores history, the year 2004 is often considered to be the start of the discipline, with Drew Endy’s construction of an artificial genome of bacteriophage T7, in which the signals controlling the expression of viral genes were rewritten in a way that could be understood by human beings [17]. And in 2005, these purely academic experiments were followed by the reconstruction of the genome of the 1918 pandemic influenza virus, a thoughtless experiment that opened up an innovative space for malicious applications [18]. The chemical synthesis of genes and genomes then became widespread. This gave rise to serious reservations because of the obvious danger of pathogens being reconstructed by malicious actors, but no restrictive measures were put in place to set limits [19]. Europe was not been left behind. In April 2006, the first joint Europe–US workshop was held in Airlie, Virginia, to identify current research and its consequences for society, including in terms of biosafety: “Synthetic Biology and Synthetic Genomes” (see the summary of the event in the box). However, no constraints were imposed to regulate the possible use of synthetic biology techniques leading to dual-use applications.
2.3. Principles of synthetic biology
To distinguish it from simple genetic engineering, the creators of this new field, specific to the life sciences, imposed four approaches:
Summary of the US-EC Workshop on Synthetic Biology, Airlie House, 24–25 April 2006
Co-chairs: Maurice Lex (EU) and Marvin Stodolsky (DOE)
Sessions:
- Biological research, empowerment by Synthetic Biology tools.
- The novel R&D arenas empowered by Synthetic Biology
- Lessons already learned in the ELSI sector, with broad discussion on the novelties posed by Synthetic Biology.
- Novel gene constructs, genomes and their resource base.
- Discussions on issues of guarding against the misuse of broadly available Synthetic Biology resources.
Synthetic biology means a range of things to different people, including molecular biologists engaged in science that may fall under the rubric of “synthetic” biology.
In session 1, the works presented included discussions of analyses of codon usage in bacterial genomes as a way to describe the “domain structure” of their chromosomes (Danchin, Pasteur, France); the role (and use) of transcription factors, both native and artificial (single chain antibody fragments, scFvs, which can mimic regulatory factors) to downregulate lacZ expression (de Lorenzo, CSIC, Madrid); the synthesis, from chemically synthesized oligonucleotides, of the minimal chromosome of Mycoplasma genitalium (H. Smith, Venter Institute); and the use of Human Artificial Chromosomes (HACs) generated using a special cloning method building on human centromeric alphoid regions, to introduce protein-coding genes of choice into human cells (Larionov, NCI).
In session 2, Drew Endy, MIT, one of the principals in the synthetic biology field, discussed the Registry of Biological Parts (http://parts.mit.edu) and how early attempts were underway to build functionalities using them. Stelling (ICS, Zurich, Switzerland) discussed the challenges facing synthetic biology (and the differences from electrical engineering), among them the lack of robustness, the (so far) poorly characterized biological “parts”, the noisy cellular background in which they must perform, the lack of isolation from other (cytoplasmic) influences, and the lack of understanding of integration into systems. Panke (IPE, Zurich) discussed experiments attempting to build artificial protein pathways that can exist and function independently of the cellular environment, starting with the glycolysis pathway from E. coli. Other talks covered the de novo design of proteins and the alteration of the function of bacterial catalysts.
Session 3 focused on societal implications. Joyce Tait (Innogen Center, Edinburgh, Scotland) discussed international issues related to the governance of synthetic biology, including processes of scientific discovery and innovation, policy and regulatory aspects and concerns being expressed by public groups. Perspectives are internationally affected by long-running controversies surrounding Genetically Modified Organisms (GMOs) and there exists a public apprehension that is not being mollified by current educational and outreach efforts, and could be exacerbated by over-enthusiastic claims of research benefits and timescales of delivery, along with arguments against the need for regulation. Shannon Nesby-Odell (CDC, Atlanta) discussed biosafety in the US, focusing principally on facility construction, safety equipment, and good laboratory practices as ways to reduce the likelihood of an accidental release. She also discussed the need for clear concise messages giving equal emphasis to the benefits of the technology, the need to promote technology advocates (e.g. in Congress), and to promote a balanced approach to politicy. Oversight policies should be proactive rather than reactive, and should involve the research community. There should be a tiered approach involving legal instruments and also engaging the community to minimize unjustified adverse perceptions. She emphasized the need for an enforcement authority, including harmonized international oversight, to provide a defence against claims of vested interest and noted that the actions of industry can unwittingly hinder progress. Dan Drell (DOE, a last-minute substitute for Mildred Cho of Stanford) discussed past Ethical, Legal and Social Implications (ELSI) programs, noting that integrating societal implications with cutting-edge science has always been challenging, especially when those carrying out social implications investigations don’t continuously work to justify why such studies are important to the success of the science. The benefits have to be explained with great candor and without overselling. Many issues will arise (and are already arising) that go beyond immediate safety and health concerns. It must also be recognized that larger decisions about what is to be done (and not done) with new technologies are made by society at large, not by the scientists acting alone.
The subsequent open discussion of the issues raised in Session 3 indicated nervousness in the scientific community about regulatory oversight and the possibility that poor regulatory choices could reduce our ability, both to respond rapidly to natural or man-made infectious agents, and to take up new opportunities to develop products of public benefit. European scientists felt that regulatory oversight in the EU was already adequate to cover the issues being included in the Berkeley Agreement. However, at other points in the discussion, the need for an enforcement capability was emphasized, along with the need to identify experiments of concern as they occur. In this complex arena, legislation, agency oversight and professional codes of practice are all needed. This is not just a challenge for biologists—numerous academic disciplines are involved. Also, the question of standard setting is at least as important as regulation in governing innovation processes for synthetic biology and it will be easier to set rules for standards when, as now, there are relatively few players involved.
Session 4, the second day, began with George Church (Harvard) talking about his work on micron-scale oligonucleotide synthesis and dealing with polymerase-generated errors that can compromise success. Santi (UCSF) discussed his work constructing altered polyketide synthase genes for the purpose of engineering novel polyketide synthases by assembling them from smaller modules. Overall, he used more than 2.5 million bp of novel PKS gene sequences to validate his approach of identifying novel, productive multi-module sets, resulting in a combinatorial approach for the production of polyketides to order. Mulligan (Blue Heron Technologies) talked about his company’s attempts to industrialize gene synthesis. Given the rapid expansion of this technology into many hands, the feasibility of regulation outside of centralized facilities may be a vain hope.
While synthetic biology is not yet a cleanly defined activity, ranging from DNA synthesis to protein reengineering, the workshop dramatized the increasing potential for synthesizing the working “parts” of living systems and thus reconfiguring them, both to study how they work and to try to engineer new capabilities. This work shows considerable promise for the development of numerous benefits to human health and society, but also raises some concerns about how it could be used and misused. Impressive work is underway on both sides of the Atlantic and continued conversations and information exchanges will be necessary and beneficial.
—Firstly, a principle of abstraction applies the known laws of life to the canonical entities of cells in order to design analogues but of a different nature, whether this concerns the elements used in the constructions or their interrelationships (architectures or regulatory controls).
This idea, illustrated in 1957 by Fred Hoyle in his book The Black Cloud, enabled him to imagine life based on a physics completely different from that witnessed in biology [20]. Beyond this romanticized view, the REPRAP (REPlicating RApid Prototyper, https://reprap.org) project aims to create a 3D laser printer that reproduces itself. The machine produces most of its own components, but it lacks crucial elements: a program (information management), an assembly line (time and space management), and specific functions such as lubrication. So it is not a real illustration of what we expect from synthetic biology. It should be noted here that this project aims to synthesize a counterpart to the chassis, forgetting the program, whereas the dominant efforts in synthetic biology do the opposite. The ultimate goal, of course, would be to synthesize both the chassis and the program.
For our purposes, the interest of approaches that use elementary building blocks different from those based on the chemistry of living matter is that they can be seen as a means of avoiding the harmful consequences of accidents or even of the malicious use of synthetic biology, called xenobiology in this context [21]. However, as access to basic materials and equipment becomes easier, it becomes increasingly difficult to control their use. This increases the risk of accidents and the dangers of misuse. By way of example, the situation can be compared to that of 3D printers, which can easily be used to illegally produce weapons for criminal purposes [22]. As gene synthesis and expression processes become increasingly accessible to a wide range of players, the possibility of effective control is illusory, and their use for malicious purposes cannot be ruled out.
—A second principle is based on the standardization of processes and components. It sees synthetic biology as belonging to the field of engineering. This means respecting standards in which the building of artificial constructs harmonizes and organizes the materials and basic principles of molecular biology in a rational way, in the form of programs expressed in a chassis. As a common starting point, the chassis is derived from existing organisms that we naively imagine to be fully characterized (which presupposes knowledge that, in reality, is neither complete nor universally accessible). We can see here that making standardized elements available to the general public makes the construction of synthetic circuits very easy. Once again, this is a feature that can be misused.
—The third principle concerns the main goal of synthetic biology. In particular, it aims to use engineering reasoning to reconstitute a living organism in order to understand what life is and discover the missing entities. Those involved in this field like to quote Feynman: “What I cannot create, I do not understand” (Figure 1).
On Feynman’s blackboard at the time of his death. https://digital.archives.caltech.edu/collections/Images/1.10-29/.
—Finally, the fourth principle takes account of Dobzhansky’s maxim: “nothing in biology makes sense except in the light of evolution” [23]. Synthetic organisms will evolve, and natural selection must be used rationally to produce variants of functions that are considered important, combining design and evolution to guide their adaptation to the conditions of interest [24].
One constant consequence of the use of evolution of synthetic organisms, whether chosen or undergone, must be emphasized: evolution has no a priori reason to go in the direction desired by human. This is an essential feature to understand when considering the applications of synthetic biology, which, although harmless in principle, can evolve into a dangerous form. Any organism, even one far removed from existing forms, that is capable of surviving in a natural environment without human help will evolve on its own, escaping its creators and turning them into sorcerer’s apprentices. This risk is well understood and taken into account by academic, governmental and even industrial governance structures. However, it is likely to be overlooked due to ignorance by a number of players, especially if they are ill-intentioned.
2.4. Chemical synthesis of genes and genomes
Originally time-consuming and difficult, and for a long time limited to the synthesis of oligonucleotides, gene synthesis has been commercially possible for many years. Synthesizing a few kilobases of DNA is now commonplace, and this technology is constantly improving. These technical advances are crucial for the development of the “natural” area of synthetic biology. In a nutshell, strings of elementary building blocks (“biobricks”) are designed for industrial use: new metabolic pathways or improved modes of regulating gene expression for a particular application, or for introducing variants of canonical nucleotides into genomes [25]. Synthetic sequences can also be used to re-create entire genomes, particularly, alas, those of dangerous pathogenic organisms, as was the case with the influenza of 1918, and also poxviruses [26, 27]. These techniques can even be used to increase their virulence [28]. Moreover, for the genomes of natural pathogens, a small quantity of an initial construct is easily amplified. A new player, artificial intelligence (AI), which has long remained in the shadows, has added to the power of malicious invention based on the vast amount of genome data [29]. Especially in its generative form, AI can manipulate and rewrite the text of genetic programs, incorporating the possible harmful expression of genes involved in the pathogenic power of bacteria or viruses [30]. This danger must be emphasized at a time when the evolution of one of these viruses, mPox, is causing a worldwide epidemic [31]. This is all the more worrying, as these nucleic acid syntheses can now be reproduced in home laboratories.
In the military field, however, one should note that biological warfare has little strategic value on the battlefield. This was demonstrated during Japan’s invasion of China with the Unit 731 programme, which began in 1932 and ended in 1945 [32]: the biological weapons used against the Chinese population (Yersinia pestis, Bacillus anthracis, Vibrio cholerae, typhus agents, etc.) caused casualties in the Japanese army. For example, the use of V. cholerae spread in 1942 in wells south of Shanghai killed hundreds of Japanese soldiers and thwarted their attacks on the ground. However, for human societies, the spread of disease has many effects other than a direct impact on health. This was clearly seen once more in the recent analysis of the economic and social consequences of the SARS-CoV-2 pandemic [33]. They are considerable. There is no doubt that an intentional biological attack, whether in a military or terrorist context, would have the same effects, which would probably be amplified by a climate of panic linked to the strategic or political context.
All this makes not only the chemical synthesis of long nucleic acid molecules critical, but also genome transplantation techniques [34]. DNA replication in selected hosts is straightforward as long as it does not lead to its expression (for example, YAC artificial chromosomes in yeast for the human genome sequencing program [35], Mycoplasma mycoides in yeast [36], the genome of cyanobacteria in B. subtilis [37], etc.). This makes it possible to obtain all sorts of new constructs and then transplant them into chassis where they will be active. However, the transplantation process remains challenging, particularly for large genomes. This is not the case for viruses, for which transfection techniques are commonplace [38]. The use of genomic synthesis based on self-splicing ribozymes used by Liang et al. [39] for the generation of viruses that are difficult to multiply is now commonplace in virology [40], certainly without the slightest control. There is indeed a warning issued by the mass media [41], which gives ideas for controlling synthesis laboratories or the equipment used for this synthesis. Unfortunately, its implementation worldwide seems illusory [42].
2.5. Unconventional uses of synthetic nucleic acids for synthetic biology
It is not uncommon for a technical invention intended for a specific use to be used, or even misappropriated, for other purposes. This is the case with DNA synthesis, an essential technique for synthetic biology. Its success has given rise to a multitude of uses, the potential harmful effects of which have not yet been fully explored. Some of the currents developments in synthetic biology are completely unconventional and original. Here are a few examples.
2.5.1. Highly parallel miniaturized computing
Provided they are in water, nucleic acids form structures consisting of double helix sections made up of strands whose sequence is complementary. In fact, the increase in entropy of the solution due to the constraint imposed on the structure of water when the nucleotide bases are accessible to this solvent with its unique physical characteristics leads to this remarkable property. The kinetics of double helix formation is fast because the process very quickly re-equilibrates the network of protons in water over a long distance. This property, which is strictly linked to the nucleotide sequence, has aroused great interest for performing highly parallel calculations [43]. For example, the classic NP-complete problem of finding subsets (cliques) of vertices all adjacent to each other in a graph, often formulated as the search for a “maximum clique”, has been solved using techniques requiring the synthesis of a group of oligonucleotides corresponding to the set of six-vertex cliques, and then implementing the selection process involving the formation of double helices specifically associating them with each other [44].
More recently, DNA has been used to create analogues of neuromimetic computation using enzymes active on DNA, whose activities and biases are adjustable, and which are assembled in multilayer architectures [45]. These logic assemblies are formed in cell-sized droplets. This computing power and extreme miniaturization pave the way for interrogating and managing molecular systems with complex content. Using DNA rather than a computer for a malicious purpose may be a way to conceal it. However, it is important to bear in mind the errors introduced during the construction of oligonucleotides, as well as the time required to build them, which have hindered the widespread use of DNA for computing. This impact can be reduced through redundancy, by multiplying constructions that are in principle identical. This is not suitable for computing, but it is perfect for archiving.
2.5.2. A new type of writing and the archiving of big data
Many archives, sometimes housed in huge buildings, bear witness to past history. Their purpose is to preserve the memory of a very large number of facts that may one day be of interest, but that do not require immediate access. Made up of text or images, they can easily be encoded in binary form. Rather than keeping the originals, a variety of media, such as magnetic tapes or optical discs, were very quickly used to reduce their storage space. However, the lifespan of these media is very short, often much less than a century. This is much shorter than what is expected of important archives. In contrast, DNA is remarkably stable, as demonstrated by the successful reconstruction of the genomes of long-extinct species [46]. As DNA behaves like the material support for a text written in a four-letter alphabet, it is easy to imagine encoding any sequence of symbols in the form of a sequence of nucleotides, which can be stored in an extremely small volume. It is also possible to make several independent copies of the same text, which reduces the negative consequences of errors or ageing, and enables the initial text to be reconstituted even after a very long time. The French National Archives have preserved the digitized text of the 1789 Rights of Man and the Citizen and the 1791 Rights of Woman and the Citizen in the form of double-stranded DNA [47]. We shall see later that, in addition to creating a new means of communicating messages or images, this use of DNA to transmit useful information can unfortunately be misused for harmful purposes.
2.5.3. Origami and DNA nanoboxes
The rational use of the subunits of DNA polymerase and other enzymes that manipulate the molecule makes it possible to assemble DNA into a variety of shapes, in a process similar to the construction of origami, a traditional Japanese craft [48]. To build an origami, a long single strand of DNA is folded using multiple smaller complementary strands chosen by the experimenter and acting as staples, where they pair up as a double strand with a region of the main strand. This folding creates predictable biocompatible static nano-architectures or dynamic nanodevices whose geometry is rationally designed, with precise spatial addressability. Peptides, proteins, aptamers, fluorescent probes, nanoparticles, etc. can be easily integrated with nanometric precision. Triggered by chemical or physical stimuli, dynamic nanodevices can, controlled by different molecular components or external stimuli, switch from one conformation to another or move autonomously, providing powerful tools for intelligent biosensing and drug delivery [49]. DNA analogues such as peptide nucleic acids (PNAs) have also been proposed for the fabrication of origami-forming nanostructures [50]. As with the majority of nanotechnology approaches, it is not easy to avoid the possibilities of dual use (see, for example, [51]).
These approaches are summarized in Table 1, where a few examples of the constructs mentioned are given. Some of these are described in the following paragraphs.
Some examples of the use of genetic program synthesis
| Theme | Examples | References |
|---|---|---|
| Genome streamlining | Mycoplasma mycoides JCVI-syn 3.0 | [52] |
| Escherichia coli | [53] | |
| Bacillus subtilis | [54] | |
| Pseudomonas putida | [55] | |
| Rebuilding what is known | Bacteriophage phiX174 | [56] |
| Influenza H1N1 1918 | [18] | |
| Mycoplasma genitalium | [57] | |
| Rewriting while simplifying | Bacteriophage T7 | [17] |
| Synthetic yeast genome (Sc2.0) | [58, 59] | |
| Mycoplasma mycoides JCVI-syn 1.0 | [36] | |
| Escherichia coli | [60] | |
| Rewriting the genetic program or metabolism through innovation | HCV | [39] |
| Optimized carbon flow | [61] | |
| Artemisic acid | [62] | |
| Biobricks | [63] | |
| Building ancestral genes | Carbonic anhydrase | [64] |
| Diterpene cyclase | [65] | |
| Thermostable proteins | [66] | |
| Polyphosphate kinase | [67] | |
| Changing the skeleton of the heredity support | l-threofuranosyl nucleic acid (TNA) | [68] |
| Peptide nucleic acids (PNA) | [69] | |
| Glycol nucleic acids (GNA) | [70] | |
| Xeno nucleic acids (XNAs) | [71] | |
| Changing nucleic acid bases | 2-aminoadénine (Z-genomes) | [72] |
| N1-méthyl-pseudouridine | [73] | |
| 5-chlorouracil, 7-deazaadénine, etc. | [74] | |
| Unnatural hydrophobic base pairs (UBPs) | [75] | |
| Creating new application | Functional synthetic biology | [76] |
| Explosives detector | [77] | |
| International Genetically Engineered Machine (iGEM) | [78] | |
| Changing the genetic code | Translation with noncanonical amino acids | [79] |
| Refactored Escherichia coli genome | [80] | |
| Changing amino acids in vivo | Norleucine, selenomethionine | [81] |
| 4-fluorotryptophane | [82] | |
| Synthetic pseudomessenger RNA | Non-immunogenic RNA for vaccination | [83] |
| Synthetic RNA for high-level protein expression | [84, 85] | |
| Synthesizing non-peptide polymers with defined sequences | Flexizymes | [86] |
2.6. Non-canonical synthetic RNAs can mimic messenger RNAs
The ongoing episode of the COVID-19 pandemic has brought to light a remarkable application of synthetic nucleic acids. In this application, vaccination with synthetic RNA stimulates mammalian adaptive immunity, usually directed against directly administered antigens, in a two-step process. First, the expression of a synthetic RNA that mimicks messenger RNA in the cytoplasm of immune system cells directs the synthesis of an antigen, the action of which then triggers the immune response.
Why is this not possible with natural RNA? To rapidly defend against infections, especially viral ones, the immune response evolved via the emergence of an innate immunity capable of recognizing a certain number of signatures universally present in pathogens, such as the presence of a genome. This led to the emergence of specific receptors that recognize free nucleic acids, especially RNA in its form of the four canonical ribonucleotides. As soon as a natural RNA binds to one of these receptors, such as the cytoplasmic RIG-I-like receptors or one of the Toll-like receptors involved in this recognition [87], the genes that code for cytokines, which ensure an antiviral response, are activated [88]. It was therefore observed very early on that this type of RNA is recognized and eliminated by the natural defence, but that this is not the case for cellular RNAs.
One of the mechanisms recently identified enables the cell to discriminate between natural cellular RNA and viral RNA [89] by dissipating energy via ATPase activity, the triggering factors of which are gradually becoming better understood [90]. It has also been observed that the extremities of nucleic acids in the cell are specifically modified (most often, for messenger RNAs, a cap at the 5′ end and a poly-A at the 3′ end) and that these modifications are different in viruses. All this means that the genomic RNA of viruses can be recognized by the immune system, but we still do not know enough about them to be able to synthesize canonical nucleotide RNAs that can be used as vaccines. Another reason why these RNAs have been excluded from medical approaches is that they are particularly fragile molecules, sensitive to the activity of ribonucleases, which are omnipresent. Finally, they can be used by enzymes such as reverse transcriptases to produce DNA copies capable of integrating into the host cell’s genome, as in the case of HIV. For these reasons, although attempts have long been made to use natural RNA to produce interfering RNA or messenger RNA for vaccine, this approach has not been as successful as hoped.
In the absence of sufficient knowledge for their routine use, research has turned to the synthesis of nucleic acids comprising modified nucleosides [91], especially pseudouridine (Ψ) or N1-methyl-pseudouridine (N1MeΨ), which alters the general structure of the molecule very little [92].
These natural analogues of canonical nucleosides have long been known to occur in certain stable RNAs, transfer RNAs, and ribosomal RNAs [93, 94]. When they replace uridine in messenger RNAs, experience shows that they are translated, opening up a new field for the use of synthetic RNA as a template for the synthesis of vaccine proteins [25]. As they escape innate immunity [73], they are excellent candidates for use via expression in immunocompetent cells [95]. Indeed, this application of synthetic biology had a considerable impact when it emerged that a synthetic RNA molecule containing these modified nucleosides yielded a highly effective vaccine against the coronavirus responsible for the COVID-19 pandemic [96] (Figure 2).
Pseudouridine and methyl-pseudouridine are very similar in shape. However, the canonical bond between nitrogen 1 of the base and carbon 1′ of ribose is shorter than the bond between the same carbon and what is then base carbon 5. This affects the speed and fidelity of decoding during translation of synthetic RNA.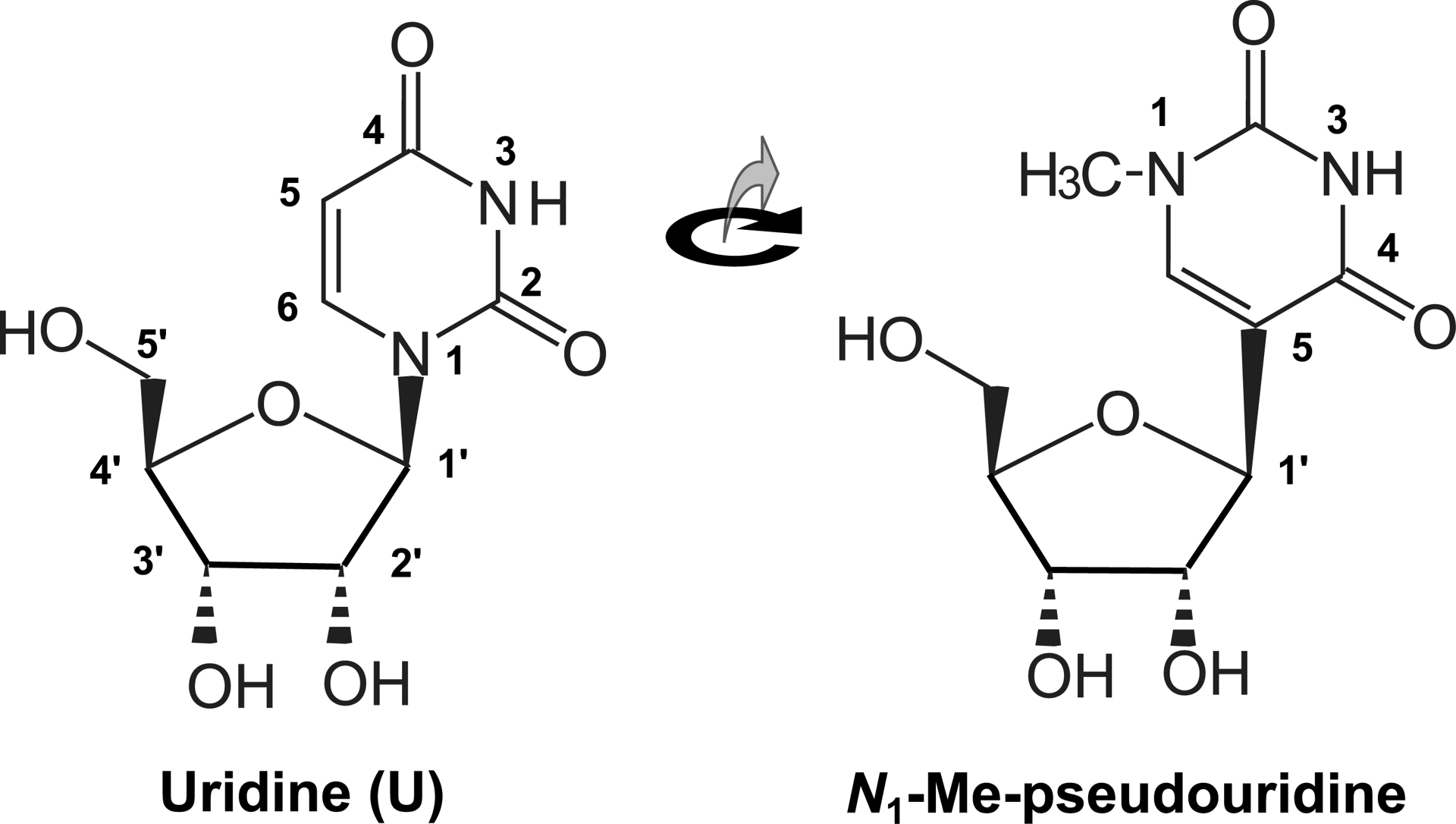
Knowing that the details of molecular events during the expression of synthetic RNA in animals could not be known, the generalization of this vaccination can be seen as a full-scale experiment involving hundreds of millions of people. Thus, today we know considerably more. The movement of an RNA in the ribosome during translation is sensitive to the sequence of nucleotides translated in groups of three (codons), which follow one another without overlap, establishing a well-defined reading frame. Depending on the context, the RNA molecule will slide and modulate the adjustment of its reading frame forwards or backwards. This property allows viruses to direct the synthesis of several proteins encoded by the same nucleotide sequence, but in different reading frames. This is how SARS-CoV-2 produces two different proteins essential for its replication, Orf1a(Nsp11) and Orf1b(Nsp12). The second proteins results from the viral genome sliding back one nucleotide in the 5′-UUUAAAC-3′ nucleotide sequence, which amounts to reading the last nucleotide, C, twice (shift −1) [97]. This is therefore a “programmed frameshift” [98], a common process in gene expression.
However, when substituted for canonical messenger RNAs, synthetic RNAs alter the accuracy and speed of their decoding by the ribosome. Recent experience has shown that this affects the reading frame of their translation, depending on the sequence in which the non-canonical nucleotides are located. We are beginning to understand the consequences of this discovery. Incorporation of N1MeΨ into mRNA causes the ribosomal reading frame to shift forward by one nucleotide at certain points in the sequence. This has been observed in vitro and in vivo after vaccination, as seen in mice and in humans with the presence of antibodies against products translated from a +1-shifted sequence during translation of the synthetic RNA encoding the vaccinating viral spike protein [99]. It is therefore an accidental “vaccination” against an antigen that is involuntarily present. This could have had an adjuvant effect, i.e. a positive one [100], and had no negative effect, as far as we know. It should also be noted that a similar process, but in different parts of the genome, occurs during the normal translation of the viral genome. To control this process during vaccination, the consequences of which are unknown, it would seem useful to replace codons containing certain N1MeΨ residues responsible for these shifts by synonyms, so as to reduce the production of coded products in the shifted phase [101]. On the other hand, this observation leads us to think that this phenomenon could be used to produce toxic variants based on this principle. This must be taken into account in future regulations authorizing these vaccine families.
2.7. Beyond the synthesis of non-canonical proteins, synthesis of polymers with programmable motifs
Synthesizing polymers with programmable sequences from a variety of elementary building blocks is of considerable industrial interest. Beyond the in vivo introduction of analogues of canonical amino acids into a synthetic construct mimicking protein synthesis (Table 1), this approach is most promising in vitro, especially with basic motifs chemically distant from amino acids. This has been achieved by the remarkable invention of “flexizymes” in Hiroaki Suga’s Tokyo laboratory for the synthesis of non-repetitive polymers [86], a revolution already proposed by Danielli half a century ago in the article cited above:
A field of enormous potential in the biological industry is the manufacture of sequence-determined polymers. There is little hope that the present-day polymer industry can develop its existing techniques to give a wide range of sequence-determined polymers. But cells have been producing sequence-determined polypeptides and polynucleotides in a vast variety for two billion years. Even limited access to such versatility at the industrial level would extend our horizons beyond what we can now comprehend [15].
Flexizymes are synthetic ribozymes designed to load a wide variety of unnatural amino acids or other polymer precursors onto transfer RNAs. This makes it possible to reprogram the genetic code in vitro by reassigning codons corresponding to natural amino acids to unnatural residues, and thus to achieve the synthesis of unnatural polypeptides or even polymers far removed from polypeptides whose sequence may be aperiodic. These polymers, whose sequence is defined by the experimenter, are of academic or industrial interest [102]. Of course, these techniques can be used for the expression of synthetic genetic programs enabling, for example, the production of toxins or chemical precursors of dangerous compounds that would be difficult to obtain otherwise. These are therefore technologies that can be “dual-used” depending on the scientific or industrial context. The use of these techniques is subject to a prior “risk analysis”, which should be carried out on a case-by-case basis.
3. A future to explore, the chassis, with at the heart of synthetic biology a neglected currency of physics: information
To conclude this brief analysis of the most common status of synthetic biology and its applications, we need to consider the often-overlooked machine. This “chassis” defines an inside and an outside, produces a copy similar to itself, and enables the expression of a program (a “recipe book”) that directs the synthesis of a replica (an exact copy) of itself. During this process, metabolism recursively transfers information from the program and manages the flow of matter and energy. However, it is important to stress an original feature that is often overlooked, as evidenced by the omnipresent use of the word “reproduction”, which is certainly not replication. This is demonstrated by the experiment of transplanting the genome of one species into another [103]. The program replicates (produces an exact copy), whereas the chassis reproduces (produces an approximate copy) [104]. This implies a set of properties that deviate sharply from the logic of standardization and may account for the lack of interest of researchers in the creation of synthetic chassis.
3.1. Information management in the cell
For example, the chassis inevitably includes time-sensitive, aged entities whose age is constrained by their physico-chemical properties in the cell’s environment. As with human machines, managing this phenomenon presupposes the existence of a maintenance process. However, this process, seldom taken into account in synthetic biology, has the unique characteristic of being necessarily endogenous, unlike industrial maintenance, which, in the vast majority of cases, requires external action. In the case of proteins, aging is intrinsically dependent on their sequence and folding. Two amino acids play a central role in this inevitable aging process: Aspartate and asparagine. They spontaneously cyclize into succinimide (with deamidation in the case of asparagine), then form an analogous residue, iso-aspartate, which locally deforms the polypeptide skeleton [105]. This universal phenomenon, long known but curiously neglected, imposes that all cells contain simultaneously a set of young and aged proteins, the latter having lost or altered their function [106]. Therefore, a set of agents must exist within them that are capable of managing this information and ensuring that when the cell produces offspring, it is, preferably or only, young offspring [107]. These discriminating agents, which are an integral part of the cell’s setup, identify classes of objects—for example, what is young and what is old—and lead them to a different fate according to their age class. In general, when thinking about the chassis required for the total synthesis of a cell that can be recognized as alive, the importance of these classifying agents, which are nevertheless present even within cells with the smallest genomes has not yet been understood [108].
We emphasize here that information is a necessary concept for understanding life. It must be taken into account in experiments or applications aimed at synthesizing living cells, in particular through the identification of these discriminating agents and their role. Unfortunately, the use of the term is particularly vague, and is not well formalized except in a restricted field of statistical physics. And yet the idea that information, more than a figure of speech, is a genuine currency of nature is a very old one. It has long been illustrated by the image of Theseus’ ship, recounted in Plutarch’s Lives of Illustrious Men:
The thirty-oared ship on which Theseus embarked with the young men offered to the Minotaur, and which brought him victorious back to Athens, was preserved by the Athenians until the time of Demetrius of Phalerus. They changed the boards as they aged, replacing them with new, sturdier pieces. Philosophers, in their discussions on the nature of change, chose this ship as an example, some arguing that it remains the same, others that it is different from Theseus’ ship.
This is because information as a fundamental currency of physics has so far only really been discussed to account for the quality of the transmission of messages made up of sequences of symbols, without having to consider the meaning of the message. Shannon and Brillouin thus proposed a theory of communication that is abusively referred to as “information theory” [109]. However, the use of this concept in biology shows that there is much more to it than Shannon’s model, as soon as we are concerned with the meaning of the message rather than its integrity: a synthetic DNA molecule does not produce the same result at all, depending on the context in which it is placed. This is a crucial observation when it comes to synthesizing life. Yet the dream of the synthetic biology engineer is that artificial cells should not be innovative (who would fly in an airplane that would innovate during the flight?). The consequence is that, like factories, cell factories will age and need to be systematically rebuilt. This poses a problem for the large-scale use of synthetic cells, and the uncertainty about their future makes it difficult to make malicious use of this original feature of all life forms.
3.2. Synthetic biology and information contagion
To conclude with the importance of taking it into account, there is still a completely different role for information when exploring potential misuses of synthetic biology. Information itself is contagious, and therefore easily subject to dual use, as we can easily illustrate in various fields. The WHO is attempting to eradicate contagious diseases specific to humans, especially viral diseases. This eradication is based on vaccination, and assumes that the majority of the world’s population is vaccinated. Alas, the spread of fear, which is useful for limiting contact and disease contagion [110], runs counter to this objective, particularly via social networks where it spreads misinformation [111]. Another negative aspect of information is the symbolic nature of a simple, explicit description of the genome of a pathogenic organism, in the form of a text written using a four-letter alphabet. Knowledge of the genome of the smallpox virus made its eradication ineffective. Since the virus sequence itself is not pathogenic, it can be propagated unhindered over the Internet, for example [112], while we now know how to synthesize poxviruses completely, as shown for horsepox [113].
There are other, more refined forms of back-and-forth between the text of a genetic sequence and its malicious concrete realization. Computers can be infected with malware encoded in DNA sequences, and biological threats can be generated from publicly accessible data, making databases of pathogenic organisms particularly dangerous [29, 114]. These databases may contain fictitious sequences that hide malicious programs that begin to run when the corresponding file is opened. To understand this, it is useful to remember that computer attacks are based on inevitable flaws in the implementation of a program in a machine [115]. In biology, these flaws are particularly numerous when it comes to exchanging material between laboratories. Just as opening an email attachment can trigger a malicious process, so can sending material made of nucleic acid. Good laboratory practice requires verifying the sequence of any received material. However, this practice is decisive in the case of hostile actions, as an apparently innocuous object may in reality be harmful or simply intended, by being different from expected, to delay or derail costly experiments [116]. Moreover, the verification process itself can be the source of malice, if a DNA segment is sent for sequencing and encodes hostile programs designed to contaminate computer equipment during sequencing [117]. As synthetic biology approaches, particularly industrial ones, combine all experimental levels, from in silico design, to in vivo evolution and in vitro production, all computer-dependent, the entry points for hacking are very numerous (Figure 3).
Back and forth between the design and synthesis of synthetic nucleic acids and the piloting of an integrated industrial process. In an integrated industrial process, synthetic biology combines the synthesis of selected genes, produced after in silico (computer-mediated) exploration, with their expression in vivo within chassis that are multiplied in fermentors, or in vitro, where they are used to develop new metabolic pathways or to synthesize novel polymers difficult to obtain with sufficient yield. The introduction of corrupted sequences can make it possible to conceal programs designed not only to enslave the control computer, but also to infect the telecommunications network linking this computer to the Internet, for example. Blue arrows: flow of information associated with nucleic sequences, either real or in text form. Red arrows: flow of commands.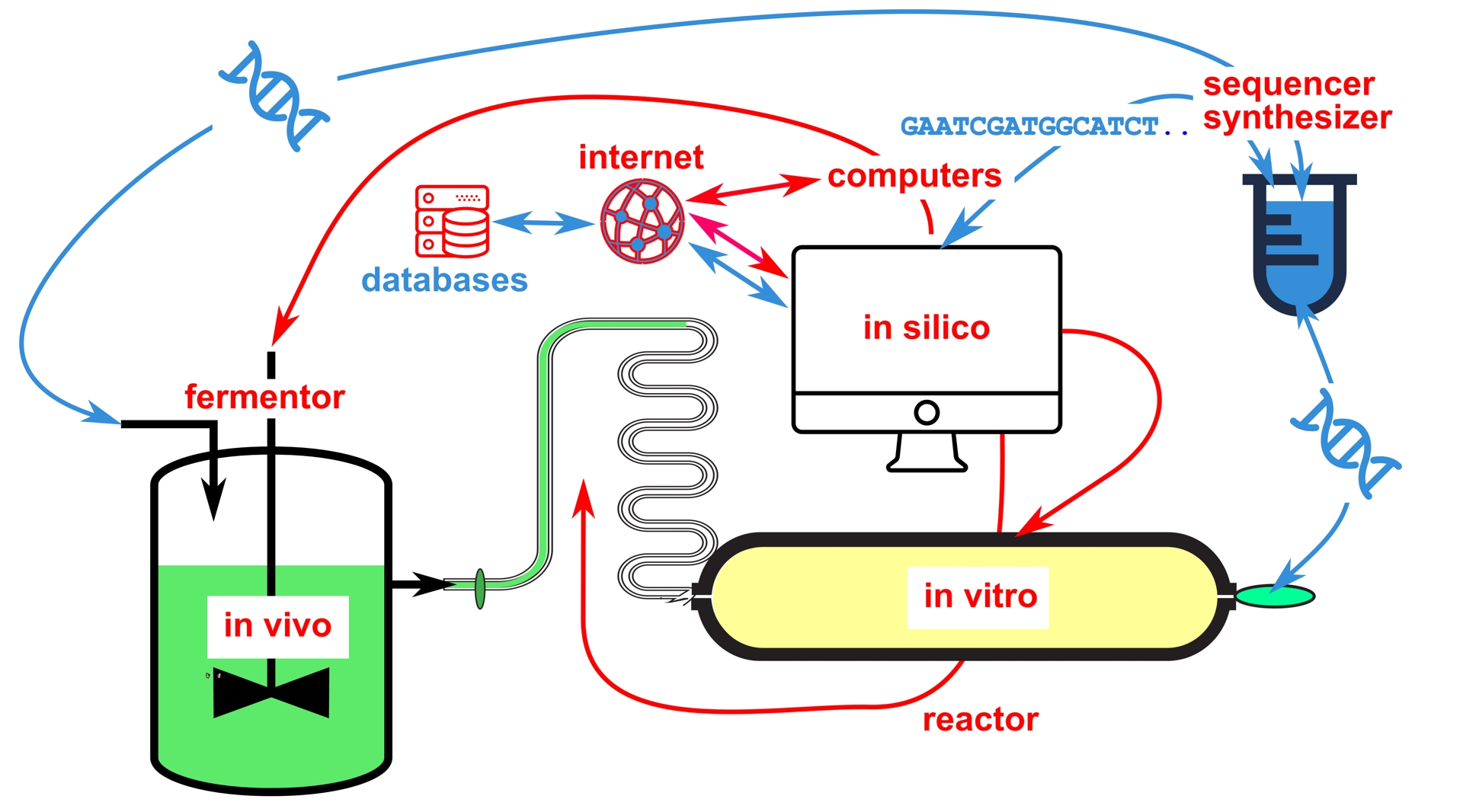
4. By way of conclusion, we need to raise awareness
When a new scientific and technical field emerges, we cannot anticipate its political, economic, societal, or behavioral impact. When driven by curiosity and inventiveness, scientific research is seen as a positive quest to advance knowledge that can lead to applications for the benefit of humanity and its environment. Unfortunately, history teaches us that this hope has often been hijacked by the quest for power. To avoid this pitfall and to define a responsible objective for scientific research, we must try to avoid misuse and unacceptable risk-taking. The raison d’être of synthetic biology is to seek to understand what life is. Along the way, this leads to the emergence of new techniques and important applications in legitimate economic sectors, such as health and quality of life, whether human, animal or plant. An analysis of the spectrum of possibilities, through the examples cited here, shows that the future of this field remains wide open and that many other uses are yet to be discovered or invented. The increasing ease of access to synthetic biology techniques means that it is becoming increasingly difficult to effectively control the flow of materials and associated resources. However, we must not ignore the fact that they can be misused for malicious purposes, or that accidents, particularly those linked to the evolutionary nature of living organisms, are always possible. So, because of its highly innovative nature, synthetic biology is an area of “dual use and risk”. And this applies to all forms of “advanced technology”: those involved in innovation and the acquisition of new knowledge need to be aware of the consequences of disclosing it. For the scientific community, this means developing a culture of responsibility that takes into account the acceptable level of risks in research and innovation, as well as the ethical implications. All too often, the danger comes not from hostile actors but from people who are reluctant to set limits on their activities, which they present as being in the general interest. This is because the pursuit of notoriety is encouraged by the current system of evaluating a researcher’s activity through their publications, based on an economic model akin to advertising. This contributes to this reprehensible behavior, which, in the absence of collective awareness, will result in the multiplication of avoidable accidents, epidemics and, ultimately, to the development of an obscurantism that rejects scientific exploration of the world. Fortunately, the scientific community has become aware of this with the San Francisco Declaration on Research Assessment (DORA https://sfdora.org/read/read-the-declaration-french/). It is essential to introduce the notion of “dual-use and risky research” into the training of researchers and engineers at a very early stage, and to know how to detect it and prevent it from developing, in particular through in-depth reflection on the ways in which research and the people who carry it out are evaluated.
Declaration of interests
The author does not work for, advise, own shares in, or receive funds from any organization that could benefit from this article, and has declared no affiliations other than their research organizations.
Acknowledgements
This work, which received no funding, benefited from discussions sparked by the I2Cell programme of the Fondation Fourmentin-Guilbert, which is recognized as being in the public interest.