

Abridged English version
In Sahel, genotype × environment interactions are often large: this is the justification behind multilocation and pluriannual trials. Because of these sizeable environment effects and interactions, the prediction of an expected yield with a linear mixed model is generally imprecise.
Improving this prediction can be achieved by modelling the environment effect. It is then partly shifted from the random part to the fixed part of a mixed model, by the use of a crop-simulation model like DHC, IRSIS, SarraH... This could not be possible with the empirical genotype × environment interactions analysis methods like AMMI and joint regression, which do not make use of environmental variables. The factorial regression method does make use of environmental variables; however, it requires their effect on the production to be linear, which might not be the case.
Unfortunately, most crop-simulation models bear a number of parameters, the estimation of which requires a specific and costly experiment. As a consequence, these parameters are usually known, but for a small set of reference genotypes. It would not be sensible to invest in a parameter estimation experiment for every new genotype that is proposed for selection.
To overcome this problem, one can notice that multisite experiments usually share a control variety for which parameters have already been estimated. In this paper, we propose to develop as a Taylor series the modelled response about the parameters of this control genotype. The other genotypes' parameters can then be estimated by a linear regression of the observed yields on the sensitivity to parameters, i.e., on the derivatives of the response with respect to the parameters. With this estimation, one can predict the new genotype responses in environments where they have not been tested. In a given location, this estimation can benefit from the available historic climatic records to estimate a distribution of probable yields.
Let denote the yield of a genotype i predicted by a crop simulation in an environment j and the observed yield. We can write:
Let us consider a control genotype, i.e., whose parameters are known or at least already estimated. Let be the vector of parameters of this control genotype and let us suppose that f is a class function in a neighbourhood of and derivable in this neighbourhood. Moreover, let us suppose in the neighbourhood of . Then, a Taylor series expansion yields:
Let and for . As f is not known in closed form, one has to estimate its derivatives by numerical approximation. The function is a function of environment j, while is a function of genotype i. Then, the local linearization yields:
This equation can be put in the form of a linear model with correlated errors:
Also, where is a vector and is the unit matrix. The dimension of X is then .
Finally, where .
We call this method APLAT for Approximation Par Linéarisation Autour d'un Témoin.
Because of the large number of columns of X, some dimension reduction method like Partial Least Squares regression is necessary. The dimension of the space spanned by the regressors is then reduced from rank of X to k. The PLS regression is usually carried out with the NIPALS (Nonlinear estimation by Iterative Partial Least Squares) algorithm, where the calculation of the components is performed simultaneously with a set of regressions by ordinary least squares. Here, the error covariance matrix is , not , generalized least squares should be used instead. As Ω is symmetric and positive semi-definite, a work around consists in factorizing its inverse, finding a matrix η such that .
Then, estimating β by PLS with regressions by generalized least squares is equivalent to consider the model:
The number of components is chosen to minimize the PRESS (Prediction Error Sum of Squares) criterion.
To calculate the confidence interval of the coefficients, we used a bootstrap technique. Let be the random variable defined by:
A percentile-t confidence interval for the th element of β is in the following form:
To evaluate the quality of the new model, we compared its MSEP (Mean Squared Error of Prediction) with that of the average model defined for our data as follows:
The data set consists of plant yields of 26 groundnut genotypes. The experiments have been carried out at Bambey (14°42N and 16°28W) in Senegal, over a period of five years from 1994 to 1998. The data of each year were kept in turn as a test sample. Yields are expressed in kilograms of pods per hectare.
We used SarraH, a crop simulation model developed by CIRAD in collaboration with CERAAS, to calculate X. Taking into account the available number of data, we estimated two of its varietal parameters.
The PRESS is minimal with six components for models adjusted without the data of 1994, 1995 and 1997. For each of the others, the PRESS is minimal with nine components. However, we decided to keep only five components, as the PRESS was not very different from its minimum value.
The APLAT MSEPs are lower than the average model MSEP, except for prediction of 1998 data. Then the prediction of yield for these models by APLAT was better than that made with the average model four times out of five.
With the APLAT method, the prediction of a genotype in a new environment comes at a relatively low price, using mostly available data, except for the environmental data, which has to be recorded for every site of the experiment, according to the crop-simulation model needs. This method seems promising, but requires additional studies with more numerous data.
1 Introduction
Au Sahel, les interactions genotype × environnement constatées lors des essais multilocaux et pluriannuels sont généralement importantes. Sur les réponses moyennes par variété et par environnement, le modèle linéaire généralement adopté s'écrit :
| (1) |
Choisir un génotype i dans un environnement j suppose d'estimer l'espérance de sa performance dans j. La précision de cette estimation est fonction de , et de . Dans cette zone du Sahel, l'environnement est variable, c'est-à-dire que et sont grands, ce qui dégrade cette précision. Pour l'améliorer, une solution est de modéliser les variations de en fonction de l'environnement par l'utilisation de modèles de simulation de cultures tels que DHC [1], IRSIS [2], SarraH [3], etc. De ce fait, une partie de l'effet aléatoire de l'environnement est reportée dans la partie fixe du modèle. Cette approche n'est pas possible avec les modèles classiques de l'interaction génotype × environnement. En effet, la méthode AMMI, Additive Main effects and Multiplicative Interactions [4] ainsi que la régression conjointe [5,6] ne tiennent pas compte des nouveaux environnements pour y prédire les réponses des génotypes. La régression factorielle [4,5] en tient compte, mais suppose que l'action des variables des environnements sur la production est linéaire, ce qui n'est pas certain.
Cependant, les paramètres des modèles de simulation de cultures ne sont pour la plupart connus que pour un petit nombre de génotypes, car leur évaluation demande une expérimentation spécifique et des mesures coûteuses.
L'objectif de cette étude se pose alors en ces termes : comment prédire le comportement de génotypes dans de nouveaux environnements en tenant compte de ces derniers, sans coût excessif ?
2 Le modèle proposé
Si nous partons du modèle de simulation de cultures, chacune des sorties de ce modèle, le rendement potentiel par exemple, peut s'interpréter comme la réponse d'un génotype i dans un environnement j :
| (2) |
Comme on l'a dit précédemment, les paramètres des modèles de simulation de cultures ne sont généralement connus que pour un petit nombre de génotypes. Considérons un modèle de simulation de cultures et un génotype de référence dont les paramètres sont connus et appelons le vecteur de ses paramètres. Alors, supposons f de classe dans un voisinage de et dérivable sur ce voisinage. De plus supposons au voisinage de . En pratique, les génotypes dont nous chercherons à estimer leurs paramètres seront choisis de telle sorte qu'ils ne soient pas trop éloignés du génotype de référence. Alors, un développement en série de Taylor à l'ordre 1 nous donne :
| (3) |
Posons : c'est une fonction de l'environnement j et une fonction du génotype i. La fonction est la dérivée partielle de la sortie du modèle de simulation de cultures pour l'environnement j par rapport à la composante du vecteur de paramètres de la variété de référence. Comme la fonction f n'est pas généralement connue analytiquement, ces sensibilités peuvent être obtenues par une méthode de dérivation numérique. Nous avons retenu tout simplement :
Avec ces notations et d'après l'Éq. (2), qui permet d'écrire , nous pouvons écrire, en négligeant :
| (4) |
Si nous disposons de I génotypes et de J environnements, nous pouvons poser le modèle suivant :
| (5) |
Le vecteur Y représente le rendement de tous les génotypes dans tous les environnements ; il est de longueur IJ, et est un vecteur formé de 1, de longueur I. Le symbole ⊗ désigne le produit de Kronecker. Le vecteur ε est un vecteur d'erreur aléatoire. Sa matrice de covariance est de la forme , avec :
Ensuite, où est de longueur J et est la matrice identité d'ordre I. La matrice X est donc de dimension .
Enfin, avec .
Nous proposons d'appeler cette méthode par l'acronyme APLAT : Approximation Par Linéarisation Autour d'un Témoin. Elle consiste à approcher, localement, le rendement prédit par un modèle de simulation de cultures, par série de Taylor à l'ordre 1 au voisinage du vecteur de paramètres d'un génotype de référence. Cette linéarisation permet, par régression linéaire, l'estimation des paramètres de ces génotypes. Par la suite, la prédiction de l'écart entre le rendement de ces génotypes et celui du génotype de référence dans des environnements nouveaux, c'est-à-dire où ils ne sont pas encore testés, pourra se faire si le climat de ces derniers est connu.
3 Estimation des paramètres et validation du modèle
Il y a en général beaucoup de paramètres dans un modèle de simulation de cultures et peu d'environnements dans un essai multienvironnement, ce qui rend souvent PI grand par rapport à IJ. Pour notre exemple, nous avons utilisé SarraH comme modèle de simulation de cultures. Ce modèle dispose de 61 paramètres, qui sont fonction du génotype. Avec un tel nombre de prédicteurs, l'estimation de β s'est faite par régression PLS, Partial Least Squares [7]. Il s'agit donc pour nous d'écrire un modèle linéaire de prédiction des rendements des génotypes pour de nouveaux environnements par les sensibilités par rapport aux paramètres des génotypes des sorties d'un modèle de simulation de cultures, fondé sur la construction de composantes orthogonales dans l'image de X. Ceci permet de réduire l'espace des régresseurs de rang de X à k dimensions. La régression PLS s'effectue selon le principe de l'algorithme NIPALS, Nonlinear estimation by Iterative Partial Least Squares [7], où un ensemble de régressions partielles par moindres carrés ordinaires est effectué, en même temps que le calcul des composantes. Ici, la matrice de covariance de ε est égale à et non à . La solution serait d'effectuer toutes les régressions partielles par moindres carrés généralisés. Mais cette matrice de covariance est inconnue. Elle s'écrit tout de même, à une constante multiplicative près, en fonction de Ω, qui elle est connue. La matrice Ω étant symétrique et semi-définie positive, par décomposition de Cholesky, il existe une matrice η tel que .
Ainsi, estimer β par PLS avec les régressions partielles par moindres carrés généralisés consiste à poser le modèle suivant :
| (6) |
Dans ce cas, la variance de l'erreur ηε s'écrit :
Le nombre de composantes à retenir est déterminé par le PRESS, Prediction Error Sum of Squares [7].
Nous avons calculé les intervalles de confiance des coefficients estimés par la méthode bootstrap [8]. Cette technique permet d'estimer la loi inconnue d'un estimateur par une loi empirique obtenue à partir d'une procédure de rééchantillonnage fondée sur des tirages aléatoires avec remise des données. Les intervalles de confiance construits sont de type percentile-t [9]. Soit la variable aléatoire définie par :
| (7) |
Donc un intervalle de confiance percentile-t pour le élément de β peut s'écrire :
| (8) |
L'évaluation de la qualité du modèle proposé est faite avec l'erreur quadratique moyenne de prédiction MSEP, Mean Squared Error of Prediction [10]. La MSEP est utilisée comme critère pour comparer différents modèles dont le modèle moyen [11], défini pour nos donnés par :
| (9) |
Le logiciel R [12] a été utilisé la fonction qui a servi pour les régression est de J.-F. Durand [13].
4 Les données utilisées
Nous avons des résultats d'essais agronomiques d'arachide menés de 1994 à 1998 sur la station expérimentale du Ceraas, située à Bambey (14°42N et 16°28O), au Sénégal. Ces essais pluriannuels ont concerné au total 26 génotypes à cycle de développement de 90 jours et répondaient à l'objectif de recherche de génotypes physiologiquement adaptés à la sécheresse.
La variété de référence choisie est la 55-437, c'est une variété hâtive de 90 jours ; elle a donc une longueur de cycle proche de celle des autres variétés utilisées. Elle a été choisie parce que ses données étaient disponibles.
Dans ce milieu à forte variabilité des pluies dans l'espace et même dans le temps pour un même lieu, nous avons considéré chacune des cinq années d'expérimentation comme un environnement (Fig. 1).

Répartition des pluies sur la station de Bambey, au Sénégal, de 1994 à 1998.
Pour valider notre modèle, nous avons réservé successivement chacune des années et estimé les paramètres des génotypes sur les années restantes. Pour chaque année, les rendements observés ont été comparés à ceux prédits par la méthode APLAT. Les rendements sont exprimés en kilogrammes de gousses par hectare.
SarraH a été utilisé pour calculer X. Compte tenu du nombre de données disponibles, seuls deux paramètres () ont été considérés parmi les 61 de SarraH. Le premier paramètre est en fait un coefficient multiplicateur qui agit sur cinq paramètres de SarraH : coefficient moyen d'angle des feuilles, coefficient de conversion en assimilat, coefficient d'efficience d'assimilation des feuilles à la phase végétative juvénile, coefficient d'efficience d'assimilation des feuilles à la première phase de maturation, phase sensible de remplissage des grains et coefficient d'efficience d'assimilation des feuilles à la deuxième phase de maturation, phase non sensible. Le deuxième paramètre est le poids moyen des gousses.
5 Résultats
Au Sahel, l'interaction G×E est largement due aux aléas climatiques, dont la probabilité peut être estimée à l'aide de longues chroniques de relevés météo au sol. Cependant, relier l'interaction G×E et la pluviométrie à l'aide d'un modèle de simulation de cultures n'est habituellement possible que pour des variétés dont on a estimé les paramètres, au prix d'une expérimentation spécifique. Le modèle APLAT permet de prédire cette interaction avec les seules données d'une expérimentation multilocale classique, sans autre instrumentation que des stations météo simples.
Pour les modèles sans les données respectivement de 1994, 1995 et 1997, le PRESS minimal est atteint avec six composantes. Pour les deux autres modèles, le PRESS est minimal avec neuf composantes, mais nous avons réduit leur espace à cinq dimensions, car le PRESS n'y est pas trop différent de ses valeurs minimales (Fig. 2).
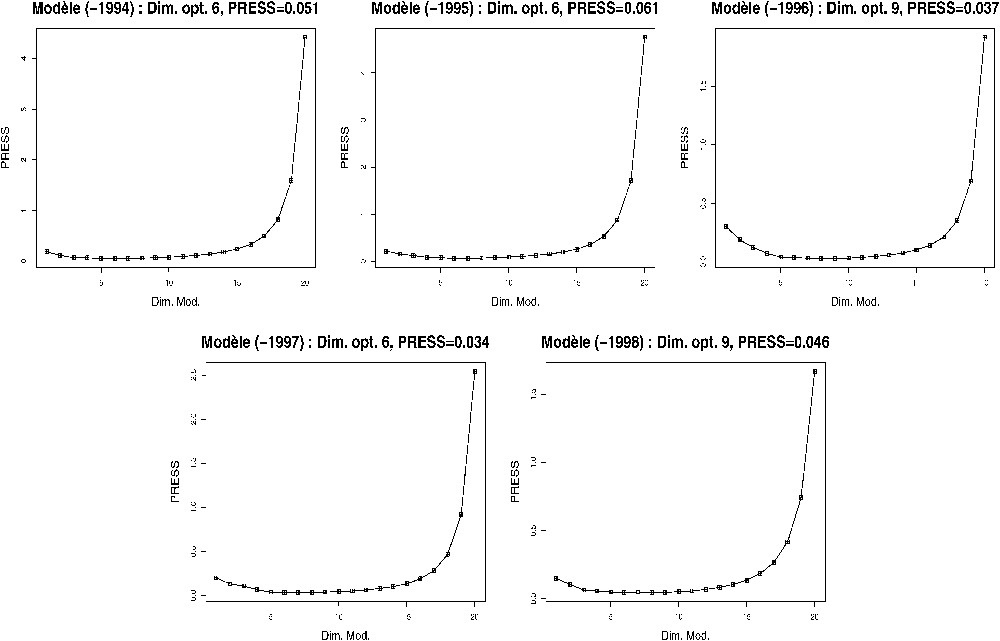
Evolution du PRESS en fonction du nombre de composantes. Le modèle (-1994) utilise les données, sauf celles de l'année 1994, et ainsi de suite.
Les coefficients des régressions PLS et les intervalles de confiance qui leur sont associés sont représentés sur la Fig. 3.
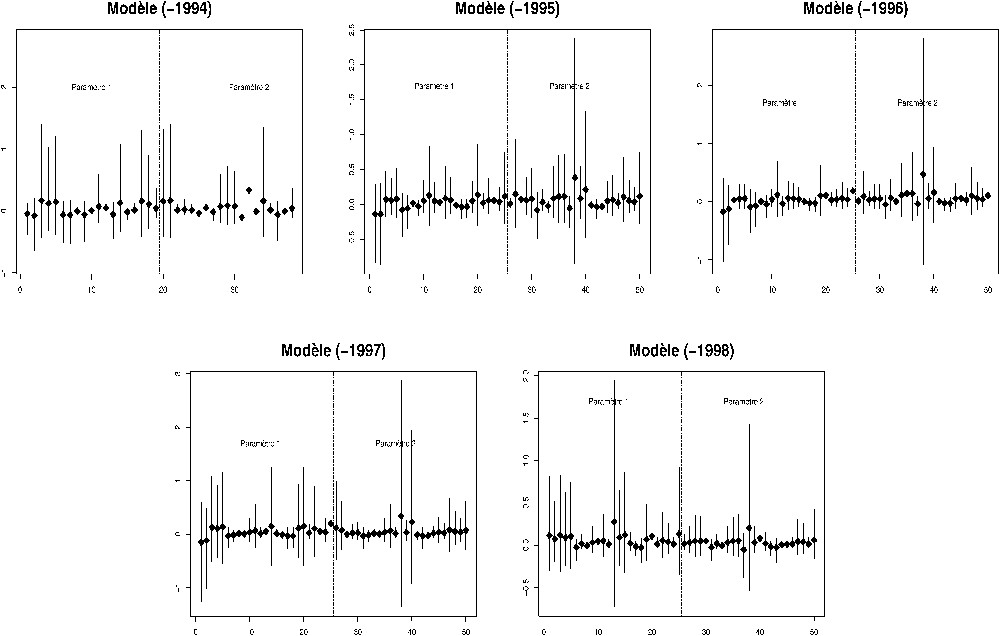
Intervalle de confiance percentile-t à 95% des coefficients estimés. Le modèle (-1994) utilise les données, sauf celles de l'année 1994, et ainsi de suite. Sur l'axe des abscisses figurent les génotypes par ordre alphabétique pour chacun des deux paramètres. Le symbole ⧫ représente l'estimation des coefficients.
Les MSEP estimées pour les modèles APLAT, sauf celle sans les données de l'année 1998, sont inférieures aux MSEP des modèles moyens correspondants (Tableau 1). Ce qui signifie que, pour ces modèles, prédire le rendement par la méthode APLAT est meilleur que par la moyenne des rendements du passé. Ainsi, quatre fois sur cinq, la méthode APLAT s'est révélée meilleure que le modèle moyen. Toutefois, cette étude souffre de la faible taille de notre échantillon.
MSEP des différents modèles APLAT et modèles moyens correspondants. Le modèle (-1994) utilise les données, sauf celles de l'année 1994, et ainsi de suite
| APLAT | Modèle moyen | |
| Modèle (-1994) | 24 687,3 | 64 651,6 |
| Modèle (-1995) | 5915,0 | 7160,6 |
| Modèle (-1996) | 35 446,1 | 37 814,8 |
| Modèle (-1997) | 10 038,3 | 18 201,1 |
| Modèle (-1998) | 118 304,9 | 84 963,6 |
6 Conclusion
La méthode APLAT peut être vue comme un outil d'aide à la décision pour la sélection au Sahel. Dans l'exemple où un sélectionneur doit tester plusieurs génotypes dans un nouvel environnement, cette méthode lui permettra d'écarter d'emblée certains génotypes qui donneront une production faible, en lieu et place d'essais multilocaux ou pluriannuels dans ces environnements contrastés ou d'une tentative de paramétrisation d'un modèle de simulation de cultures qui implique un coût élevé. Son attention sera portée par la suite sur l'ensemble restreint des génotypes retenus avec APLAT, où il pourra appliquer les schémas classiques de sélection.
Cette nouvelle approche semble prometteuse, mais il faut des études supplémentaires. Notamment disposer de données agronomiques plus conséquentes pour l'éprouver.
Remerciements
Nous remercions Danièle Clavel pour les données de l'étude et Jean-Claude Combres pour toutes les discussions autour du modèle SarraH.