


 CC-BY 4.0
CC-BY 4.0
1. Introduction
The use of numerical models for studying subsurface flow has become common practice in hydrology and petroleum engineering over the last 50 years [Renard and De Marsily 1997; De Marsily et al. 2005]. However, one of the major questions that still poses a problem is that the data needed to build an accurate model are incomplete in essence. Although contemporary computers are growing ever more powerful and capable of describing the relevant flows with increasing details, the required input data growth imposes a major increase in computing facilities if one wants to explore correctly the uncertain input parameter space in order to make the best decisions [Gorell et al. 2001]. In many applied geosciences issues, the basic concern is to recover, to store or to follow some fluid, waste or even thermal energy in subsurface formations at good economical conditions, while minimizing overall environmental risks. Most of the associated transport processes occur in the porosity of natural rocks, perhaps fractured, so studying flow in porous media at several scales is a major issue. In order to proceed, a concise macroscopic description of flow in porous media encompassing several scales without knowing the exact structure of the subsurface at lower resolution scales must be obtained.
Basically one wants to be able to estimate with some accuracy the average value, as well as the associated variance of any simulated value of interest. Knowledge of the full probability distribution is in general not required, although knowing if the resulting distribution is approximately Gaussian or not may be important. In the general case, when the driving equations relating input data to output observables are strongly non-linear, extensive Monte-Carlo sampling of the input parameter space is required to get estimations of these output statistical quantities. A typical subsurface model is generally described by some random fields of say porosity, permeability maps conditioned to several field observations, sedimentary layer shapes, aquifer positions, etc…These random maps depend in turn on some hyperparameters of statistical nature such as variance, drift, correlation scale: that is the aim of geostatistics that will be presented with more details in Section 2.1. In addition, some man-controlled parameters such as the position of wells and the associated flow rates enter as input data in the model. For applications, that influence of that set of parameters may be sampled by simulation to select the best position and management of the wells.
Using such models, we are led to consider high dimensional parameter spaces, both for the random set of natural data, and for the man-controlled parameters. Consider a parameter space of N = 100 dimensions, and by hypothesis, let us assume that each parameter can take only 2 values. An exhaustive exploration of that parameter space will imply being able to perform 2100 independent runs, that is clearly impossible even with hypothetical quantum computers. In addition, in current models, most parameters belong to some continuous interval, increasing the effective dimensions of the parameter space. So following any exhaustive approach is a dead end. Many alternative sampling techniques were developed [Zhang 2001]. Experimental design techniques coupled with machine learning methods are being developed [Scheidt et al. 2007; Santos Oliveira et al. 2021, and references therein].
That implies that some systematic workflow is to be built in order to reduce the number of dimensions of the effective working space under consideration. As that situation presents some similarities with statistical physics, some bridges between both disciplines can be expected: a description of these connections may be found in Noetinger [2020]. To sum-up, similar issues are at the heart of one the most active area of complex systems understanding, the so-called spin glasses for which G Parisi was awarded the 2021 Nobel prize in physics [Mézard et al. 1987; Zdeborová and Krząkała 2007; Zdeborová and Krzakala 2016]. In the geoscience side, some reviews illustrate similar issues [Gorell et al. 2001; Floris et al. 2001; De Marsily et al. 2005].
The goal of that short paper is to suggest some avenues of research in order to provide answers to the following questions:
- What is the amount of information that is required to build a useful numerical model with a degree of sophistication consistent with the input knowledge.
- is it possible to build a model that may be continuously improved as our knowledge of the particular aquifer increases along with the volume of data acquisition.
The paper is organised as follows: in Section 2, we provide some general elements. Then a focus is given in Section 2.1 about geostatistics, before giving some elements about information quantification in Section 2.2. Single phase flow problem serving as a basis for most of our discussion is introduced in Section 2.3. Then we discuss up-scaling applications in Section 3.1 by discussing the scale and support effects. Non linear issues implying a strong feed-back between the medium structure and the flow are discussed in the case of two-phase flows in Section 3.2. In Section 4, we present some ideas allowing to merge the preceding considerations between geostatistics, up-scaling and information theory for practical applications. Finally some fruitful research avenues are suggested for future investigations.
2. Medium description, up-scaling issues
We consider a subsurface formation of typical kilometric scales. In Figure 1, the overall scales of the considered aquifer are represented, as well as the corresponding discretization mesh of interest, choosen cartesian for sake of simplicity. Each grid block may be populated by parameters such as porosity 𝛷(r), permeability k(r) and any other relevant parameter. That can be drawn using some deterministic or geostastistical software.
Geometry of the problem on a simplified 2D section of a subsurface model domain 𝜔. A coarse grid made of blocks 𝛺 of typical size L is super-imposed to a geological fine grid of typical size 𝛥 in order to solve the conservation equations of interest. The intermediate scale 𝜆 serves in posterior treatments for checking the overall consistency of the model. Reprinted (adapted) from Colecchio et al. [2020] Copyright 2020 with permission of Elsevier.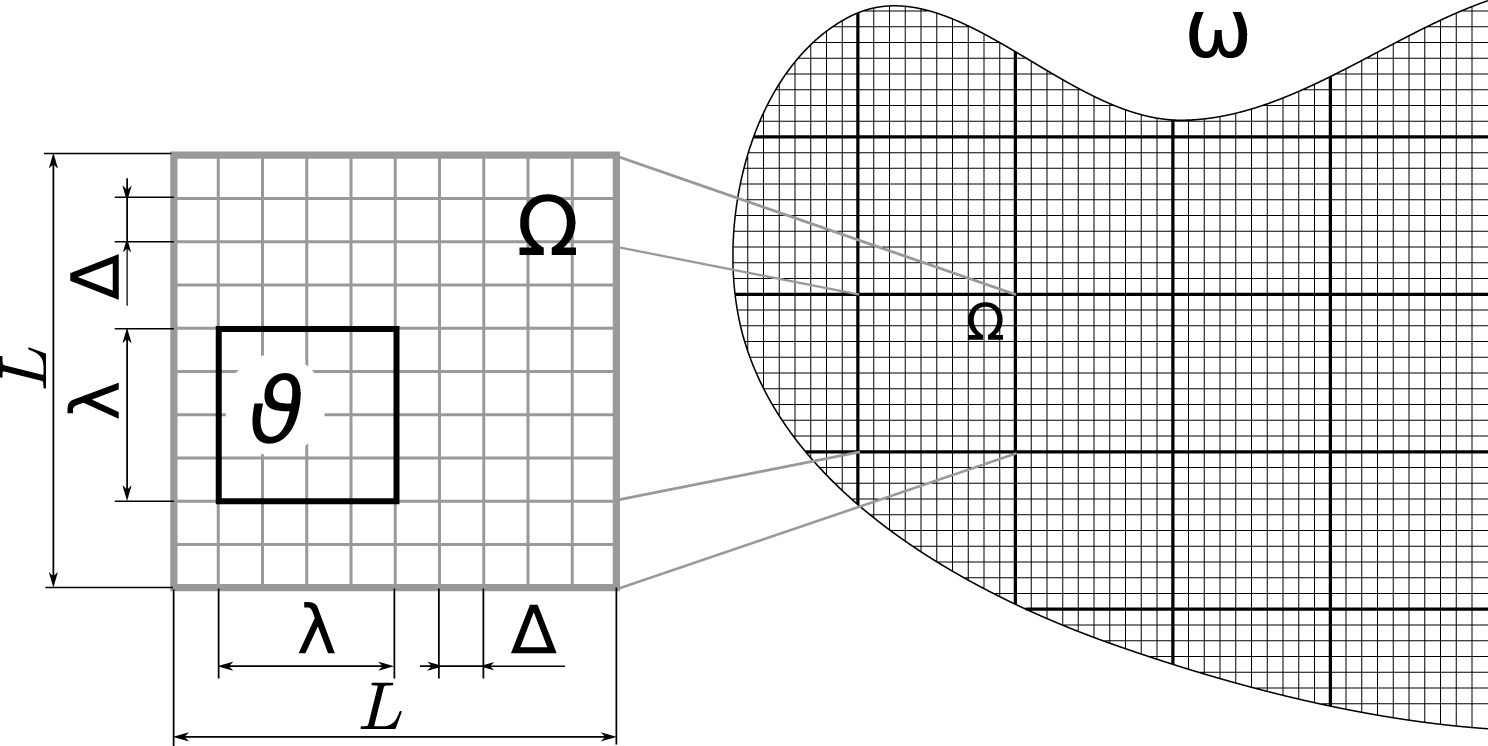
2.1. About geostatistics
Modelling subsurface formation using numerical models implies to account for the fact that any local quantity of interest may depend on position vector r. In most cases, for example the quenched1 positive permeability k(r), is represented as being a random function of position. It is characterized by some mean-value and fluctuations that are measured using field data (an issue in itself!). That is the aim of the so-called geostatistical approach, originaly founded by Matheron [1963], Krige [1976], De Marsily et al. [2005], Chiles and Delfiner [2009] and developed by several others, that form the conceptual basis of several popular commercial softwares. The basic idea is to interpolate known measurements on a given support on several locations by inferring some underlying statistical structure. Notice that the primary random mathematical objects are functions or fields that are characterized by an infinite number of degrees of freedom. So the most natural embedding formalism that encompasses it is the so called field-theory employed in both statistical mechanics or particle physics [Noetinger 2020; Hristopulos 2020]. Another related issue that was pointed-out by Tarantola [2005] is that working with continuous variables implies that there is not a reference entropy measure allowing to quantify easily the information of a geostatistical distribution: the overall results are sensitive to the coordinate system used by the modeller. At this stage, the associated reference “non-informative” reference distribution [Tarantola 2005; Abellan and Noetinger 2010] is not determined. That explains some deep theoretical and practical difficulties for generalizing the approach to curved spaces or to non-uniform grid, Mourlanette et al. [2020]: such a situation may occur if tectonics imply strong deformation of a sedimentary basin. In most practical cases, some implicit cartesian assumption is made. Probably it could be justified using the sedimentary nature of most aquifers. In the similar statistical physics case, it may be shown that the continuous Boltzmann–Gibbs distribution that is the basis of most applications may be derived by a suitable limit of the underlying quantum mechanics processes that poses paradoxically less difficulty owing to their discrete nature (Setting-up a natural probability measure to a 6 face dice rather than to a continuous process). In geoscience, approximate Log-normal distributions (the logarithm of the conductivity is a Gaussian distributed variable) were observed at the core scale within several geological environments [Gelhar 1993]. Note that in most cases, the amount of data is not sufficient to provide the form of the probability distribution function (pdf) of k, and higher order correlation functions are almost impossible to be determined from field data. In the current modelling practice, they are implicitly fixed by choosing some additional assumptions based on geological expertise on similar environments. As a consequence, even the input stochastic model is questionable.
Another class of models that intend to add information on high order correlation functions are multipoint or so-called process-based models, intending to reconstruct the apparent randomness of the subsurface by simulating the long term history of the formation using some dynamical physically based model: Diggle et al. [1998], Granjeon and Joseph [1999], Hu and Chugunova [2008], Michael et al. [2010]. These models introduce more physically based parameters and are more realistic. However, they may depend on assumptions regarding the time-dependant external forcing at their boundaries, introducing stochasticity in a somewhat another manner. An essential specificity of geosciences is the so-called measurement support effect: any data is obtained using some instrumentation that averages the details of the process at hand on a characteristic length that depends on the physical process. That scale may vary from some centimeters for laboratory/logging tools, to hectometers in geophysics corresponding to the typical wavelength of geophysical waves, or to the support of transient well tests interpretation. Any measurement is characterized by a support scale characterizing the measurement itself, and by another spatial scale that is the typical resolution.
Finally, due to the data scarcity, it is necessary to up-date any prior model of the subsurface by accounting for the additional data that are continuously enriching the available information. That new data can be provided by pressure and rates measurements at some producing wells, time-dependant tracer concentration showing connections between several regions of the subsurface etc…This is the so called inverse problem issue that was addressed by many authors [Jacquard 1965; LaVenue et al. 1995]. It is well-known that such problems are ill conditioned and that some regularization is required [Tarantola 2005; Oliver and Chen 2011, and references therein]. That can be achieved accounting for a prior geostatistical structure [LaVenue et al. 1995; Le Ravalec et al. 2000; Hu and Chugunova 2008] that is easier to carry-out considering gaussian priors.
2.2. Quantification of information
As data may be scarce (but even redundant), it is essential to be able to quantify the amount of information provided by a measurement, as well as the quantity of information that is required to make faithful predictions. That idea can be formalized using information theory, as attempted in Abellan and Noetinger [2010, and references therein]. A quantitative estimate can be defined introducing the relative entropy (Kullback–Leibler divergence) between posterior and prior distribution that serves as a non-informative reference distribution. That quantity is defined by:
| (1) |
| (2) |
| (3) |
| (4) |
| (5) |
Left: A typical realization of a random map 2D section of a subsurface model on a domain 𝛺, representing Log(k). The superimposed circles correspond to N = 5 physical measurements of permeability on a support scale with the corresponding radius, with several realistic values. The average distance between the circles corresponds to the coverage of the area. In a perfect situation, all the area should be covered, that is seldom the case. Right: the amount of information provided by N local measurements defined by the relative entropy of posterior distribution versus prior. Note the saturation of the information once the medium is well covered by the measurements, 𝜇 is defined in the main text. Lx and Ly are the overall size of the domain in the x and y directions, and denote the correlation length in corresponding directions. N∗ is thus the number of correlated volumes inside the overall domain. It corresponds to the crossover the transition of information content between independent measurements and redundant ones. Copyright 2020 with permission of Springer-Nature.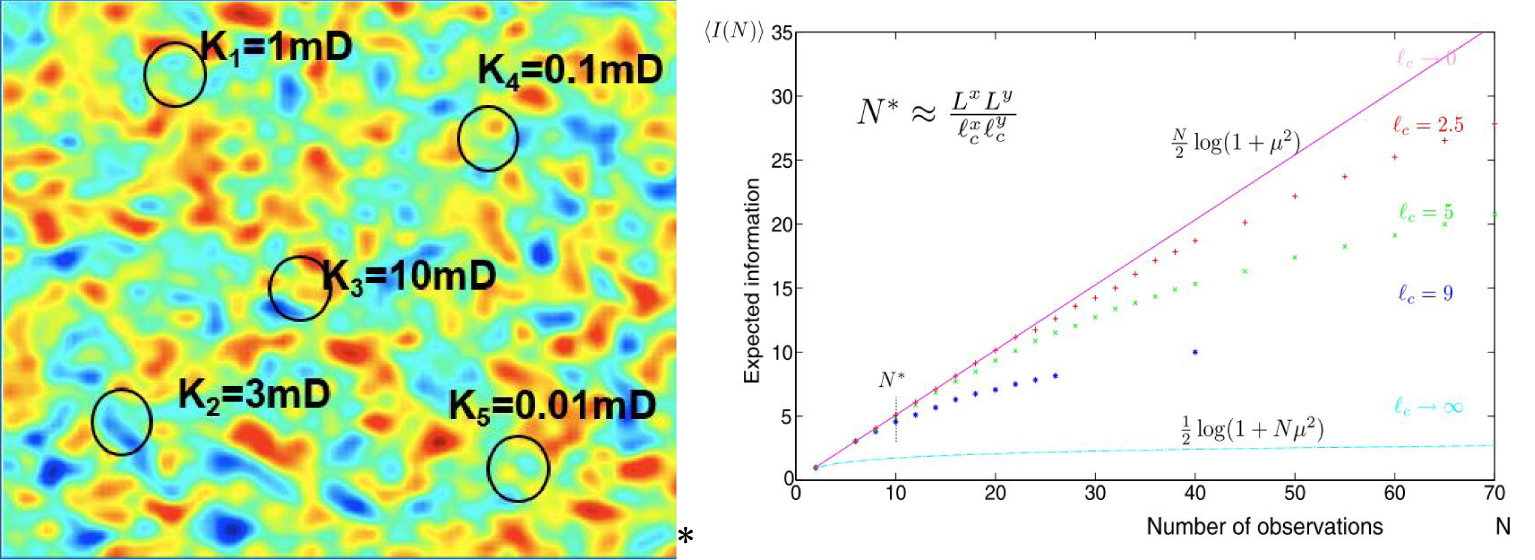
2.3. Fluid-flow modelling
In most cases, modelling fluid flow in a porous formation [De Marsily 1986] leads to solve a diffusion-like equation that reads:
| (6) |
The basic issue is to be able to solve such equations, accounting for both the the effect of heterogeneities, and to be able to quantify the related uncertainties. In that context, analytical methods were developed by hydrogeologists [Gelhar 1993; Dagan 1989; Indelman and Abramovich 1994; Abramovich and Indelman 1995; Renard and De Marsily 1997], mathematicians [Jikov et al. 2012; Armstrong et al. 2019] and physicists, among other [King 1989; Noetinger 1994; Hristopulos and Christakos 1999; Nœtinger 2000; Attinger 2003; Eberhard et al. 2004; Teodorovich 2002; Stepanyants and Teodorovich 2003].
On the numerical side, a possible strategy is to transfer the small scale spatial fluctuations to a large scale support that encompasses the low spatial frequency components of the fields of interest. The calculations are carried out in practice using some numerical model in which the Laplace equation is solved using a grid of resolution L generally considerably much coarser than the input fine geological grid 𝛥 (notations in Figure 1), because the available computing power leads also to continuous improvement of local geological 3D representations. This implies obtaining a coarse grained Laplace equation with a renormalized conductivity map accounting as best as possible to the local subgrid variations. In the case of multimodal distributions, in which connectivity aspects are dominant, specific methods can be developed within the framework of percolation theory, such as real-space renormalization techniques [Berkowitz and Balberg 1993; Hunt et al. 2014; Hristopulos 2020].
In the stochastic context, a strategy is to average the solution of Equation (6) to get the average head (or pressure) ⟨p(r,t)⟩ in which the ensemble-average ⟨⋯ ⟩ is to be taken on the disorder of the conductivity field k(r) corresponding to a Monte-Carlo average over the disorder of the medium. Then, one can look for the equation that may drive that average head2 [Noetinger and Gautier 1998].
3. About flow up-scaling
3.1. Single phase steady state up-scaling
It can be shown that under quite general hypothesis (statistical stationarity and convergence conditions) that the low frequency components of the average potential ⟨p(r,t)⟩ is driven by an effective equation that reads:
| (7) |
Up-scaling geometry. The coarse block of size L have a detailed conductivity map given by geology. It is up-scaled by solving a steady-state quasi Laplace equation to determine an effective conductivity in the mean flow direction. Boundary conditions are usually no-flux parallel to the imposed mean flow, or periodic.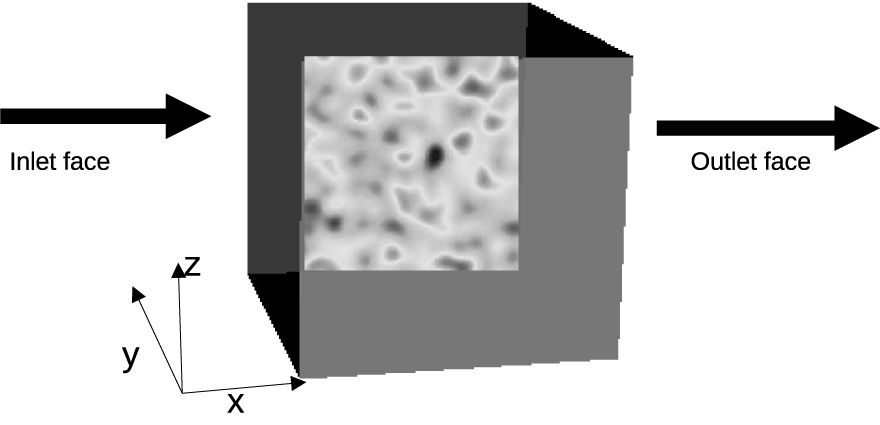
Monte Carlo study of the dependance of the effective conductivity pdf with coarsening scale 𝜆. The overall flow is solved using several realizations of the input log conductivity map (left). The associated local dissipation map (center) allows to evaluate a distribution of coarsened effective conductivities averaged at intermediate scale 𝜆 [Colecchio et al. 2020]. The associated pdf’s are plotted (right). The self averaging feature is highlighted by the sharply peaked distribution around the geometric average for 𝜆 = 128 units. Reprinted (adapted) from Colecchio et al. [2020] Copyright 2020 with permission of Elsevier.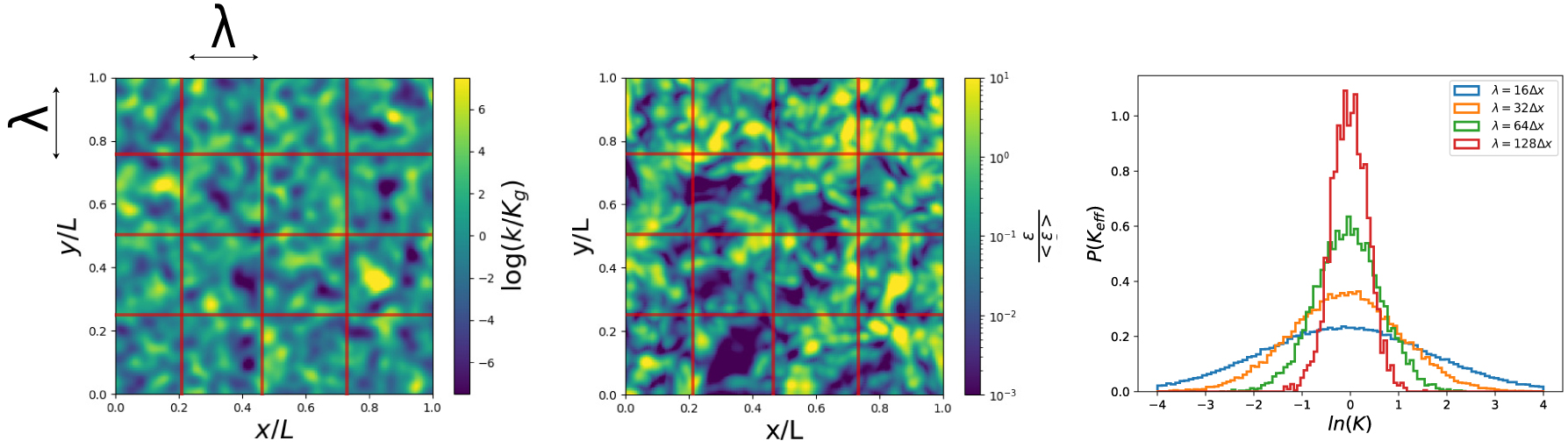
Monte Carlo study of the effective conductivity pdf with coarsening scale 𝜆. The overall flow is solved using several realizations of the input bimodal map with conductivity contrast of 104. The associated local dissipation map (center) highlights the localization phenomenon and allows to evaluate pdf’s of coarsened effective conductivities averaged at scale 𝜆 [Colecchio et al. 2020]. The resulting scale-dependant pdf’s are plotted (right). As the scale is increasing, the two peaks merge, the bimodal distribution disappears and becomes close to a log-normal distribution. The convergence to this asymptotic distribution shows critical slowing-down when the facies proportions are close to percolation threshold. In the infinite contrast case, scaling-laws are recovered [Stauffer and Aharony 2014]. Reprinted (adapted) from Colecchio et al. [2020] Copyright 2020 with permission of Elsevier.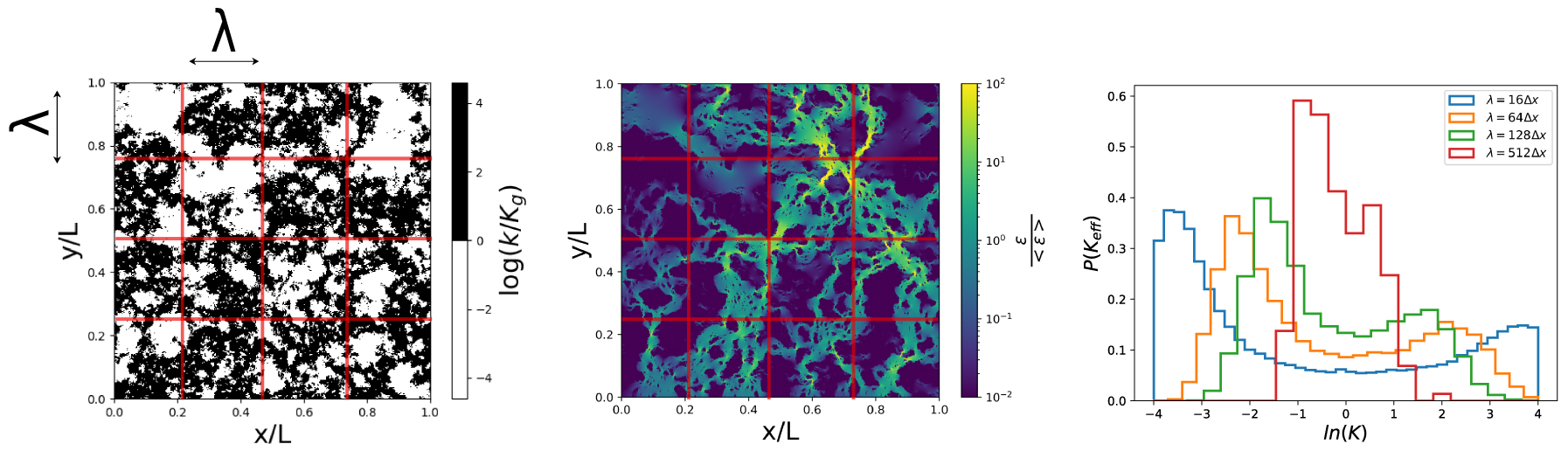
3.2. About the interaction between the conductivity spatial distribution and the flow pattern
In several situations, such as when considering multiphase flow flows in heterogeneous media, some strong coupling between the flow and the underlying medium may occur. This can be the case when considering water displacing oil, CO2 injection etc…This may give rise to an instability driven by a mechanism is similar to the well-known Saffman–Taylor instability that leads to viscous fingering if the displacing fluid is more mobile than the fluid initially in place. This emergence problem was studied by many authors such as Saffman and Taylor [1958], Homsy [1987], Tabeling et al. [1988], Tang [1985], Shraiman [1986]. A generalization to imicsible two phase flows was carried-out in the paper of King and Dunayevsky [1989, and references therein]. In that case, it appears a well defined sharp front separating both phases moves at the local velocity of the fluid, as shown in Figure 6, top. That front may be in unstable, by the same mechanism than the Saffman–Taylor instability, as shown in Figure 6, bottom. In the unstable case, an amplification of the heterogeneity effect is expected, while some smoothing arises in the stable case. The intuition suggests that a highly mobile
fluid will follow high velocity paths, its presence amplifying thus that advantage by a positive feed-back loop. This is the so called channeling issue. This problem was addressed by De Wit and Homsy [1997a, b], and revisited in the stochastic context by Artus et al. [2004], Nœtinger et al. [2004], Artus and Noetinger [2004], merging perturbation theory within the framework developed by King and Dunayevsky [1989]. In order to be more specific, the underlying equations reads:
| (8) |
| (9) |
| (10) |
Here, S(r,t), 𝜆(S(r,t)) and f(S(r,t)),S denote respectively the water saturation (local % of water, total mobility and the so-called fractional flow of water). This set of coupled equations may be solved numerically (it is at the heart of any multiphase flow in porous media simulator, to which additional complexities such as phase transitions and boundary condition management must be added). The saturation equation (9) is hyperbolic, leading to the formation of a shock front, whose stability is controlled by the jump of the total mobility 𝜆(S(r,t)) at the front.
Dynamics of a two phase flow front moving in a heterogeneous rock, imposed mean flow from left to right, underlying random log normally distributed conductivity map top (a) stable case (b) Y averaged saturation at different times, bottom (c) fingering in the unstable case, (d) associated Y-averaged saturation at different times.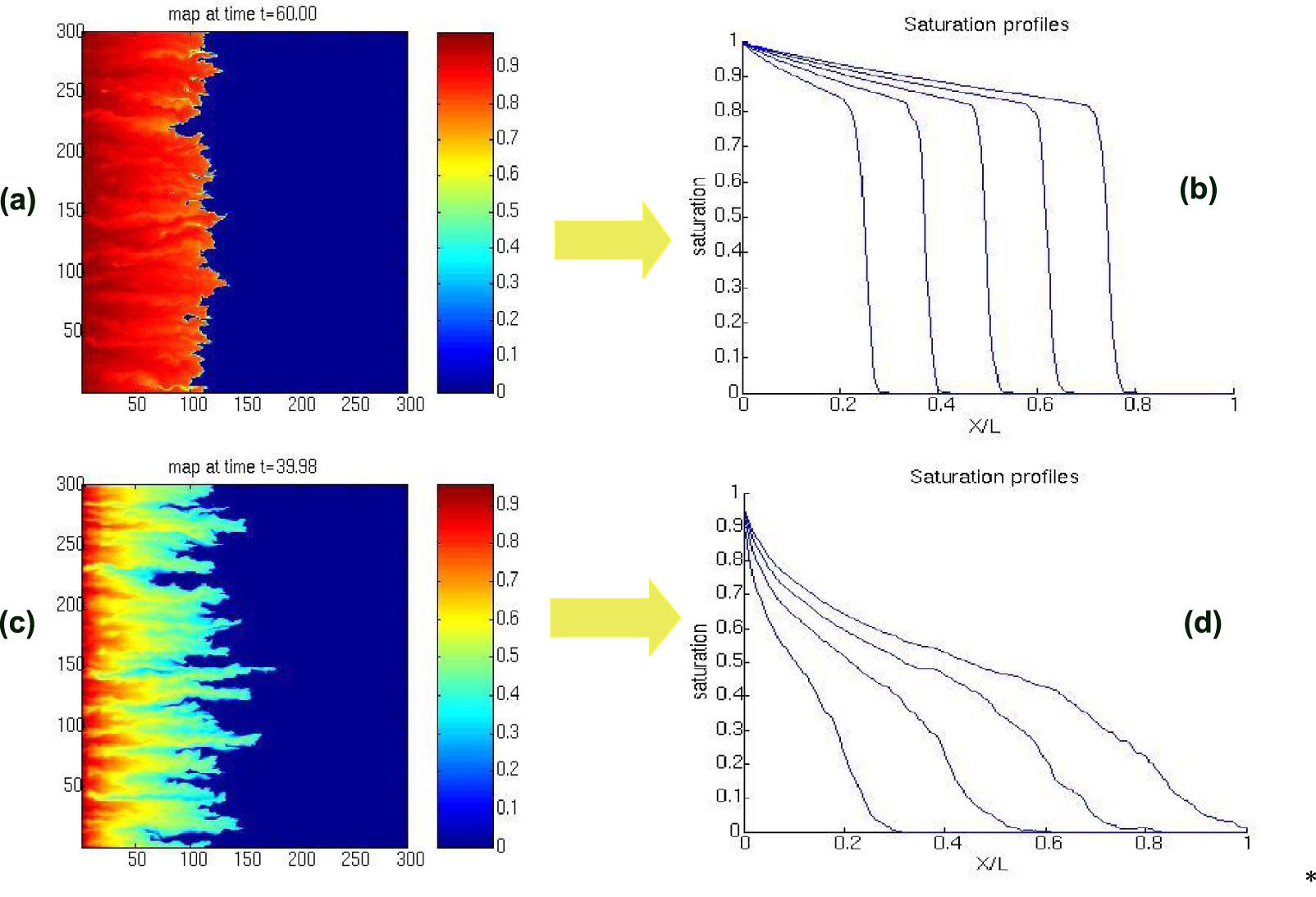
The technical difficulty for setting-up a perturbation expansion comes from the presence of the front that implies a mobility jump that renders perturbation theory a bit tricky [King and Dunayevsky 1989; Nœtinger et al. 2004]. The difficulty may be avoided by a suitable change of variable, using a working variable x(S,y,t) rather than S(x,y,t). It is thus possible to introduce the function x(Sf,t), in which Sf is the saturation of water just behind the front Mf is the corresponding total mobility jump Mf =𝜆 (Sf)∕𝜆(S = 0). The randomness of the underlying conductivity field propagates to the randomness of x(Sf,t), of average value ⟨U⟩t. At long times, the associated two point correlation function can be shown to converge to a well defined function in the stable case, while in unstable case it diverges, a manifestation of the spreading of the front [Tallakstad et al. 2009; Toussaint et al. 2012]. A possible approach of practical interest close to the single phase flow approach would be to look at an effective equation driving the ensemble-averaged water saturation ⟨S(r,t)⟩, or the Y-averaged saturation S(x,t). A diffusive-like regime arises in the case Mf = 1, that corresponds to a marginal stability criterion. In the general case, several proposals were reported long ago for characterizing the emerging large scale transport equation [Koval 1963; Todd et al. 1972; Yortsos 1995; Blunt and Christie 1993; Sorbie et al. 1995]. In the unstable case, one can consider that long fingers parallel to the imposed flow may be treated as a stratified medium. This leads to modify the fractional flow function with an ad-hoc change [Koval 1963]. In the stable case, it can be shown that the competition between the disorder that distorts the front and the viscous forces that tends to sharpen the front [Nœtinger et al. 2004] must lead to another form of the effective fractional flow, including some macrodispersion representing the net effect of the averaged disorder. In the infinite contrast case (e.g. immiscible gas injection) Diffusion Limited Aggregation (DLA) models were proposed, leading to a very rich literature involving percolation invasion models, fractals [Witten and Sander 1981; Wilkinson and Willemsen 1983; Paterson 1984; Masek and Turcotte 1993] with many contributions of SP.
4. Geostatistics, up-scaling and inverse modelling
Our original issue was to know the relevance of a complex model in regard to the input knowledge. It appears that if one is interested by predicting the average and variance of the output of some transport process, a compromise must be found between the overall accuracy of the calculation involving a high resolution grid implying large computing costs, and the statistical accuracy that requires being able to perform a huge number of Monte-Carlo simulations4 required to get representative statistical averages of the process under consideration. The overall simulation budget B(Sizemodel,NMC) in terms of hours of CPU depends on the model size Sizemodel and the number of Monte Carlo simulations NMC. The latter depends on the number of relevant input parameters that control the overall behaviour of the system. It is possible to determine the couple (Sizemodel,NMC) such that the variance 𝜎2(Sizemodel,NMC) of the prediction errors of the simulation output is minimized under the constraint of fixed B(Sizemodel,NMC). As presented in the preceding section, up-scaling techniques may provide some tools allowing to get a case-dependent prior estimate of that variance without running the whole set of simulations.
Practitioners want to get estimations of the average value and of the variance of the output of interest (water supply, heat recovery etc…). So the approach developed by Abellan and Noetinger [2010] could be carried-out in the prediction space. The advantage of such an approach will be to be closer to operational quantities of practical interest, and also to be more independent on the dimension of the input parameter space. Such an avenue needs to be developed.
5. Conclusions and some perspectives
In that short note, we discussed some ideas and previous findings illustrating mainly the interaction of the quenched disorder of the natural media present at all scales to the flow. It appears that hydrologists could be greatly helped by developing an approach combining pragmatic practice, advanced averaging techniques and optimization techniques merged within a framework of physically guided artificial intelligence techniques. An approach is to draw the “phase diagram” of the problem at hand, i.e. the set of dominant parameters controlling the overall behaviour of the system, and providing descriptions of the critical behaviour of the system between the different regions of the phase diagram. Information theory concepts can be helpful to quantify the disorder and the amount of information of the system, providing useful links to statistical physics concepts and methods.
Such an approach is evidently process-dependant and must be adapted for heat or tracer transport and mixing, as well as reactive flows, issues that were not discussed in that short paper.
A promising approach would be to map the linear systems to be solved that are essentially of Laplacian nature into random matrix theory close to random graphs theory [Mohar 1997; Bordenave and Lelarge 2010; Potters and Bouchaud 2019]. That area of research is a fast growing field with applications for modelling networks such as the Internet, urban and road traffic, smart electrical networks, brain modelling, finance etc…Some applications may be found in the modelling of flow in fractured rocks [Hyman et al. 2017, 2019]. A possible mathematical approach is to study the spectrum of the large matrices obtained for solving the quasi Darcy flow equation that depends randomly on the geological input parameters. That may provide information about the effective number of relevant degrees of freedom that must be retained to describe the system [Biroli et al. 2007]. Depending on the degree of disorder, some eigenvalues of the associated Laplacian matrix can be expected to provide information while other eigenvalues may follow some universal distribution such as a Marchenko–Pastur distribution [Marchenko and Pastur 1967]. Such topics are deeply connected to classification methods by neural nets [Louart et al. 2018; Dall’Amico et al. 2019].
Finally, as illustrated by De Marsily [2009], water supply issues will become more and more critical, implying great applied and academic research efforts. As it was explained in present paper, expecting tremendous computing power cannot be the single option. The community will have to rely on innovative approaches at the cutting edge of modern science, as our mentors did [Matheron and De Marsily 1980; De Marsily et al. 2005].
Conflicts of interest
The author has no conflict of interest to declare.
Acknowledgements
The author is indebted to MM Alexandre Abellan, Alejandro Boschan, Ivan Colecchio Pauline Mourlanette and Alejandro Otero for their useful contributions.
1 The term quenched is employed in statistical physics of disordered systems, it corresponds to systems having a fixed but unknown disorder without thermal fluctuations that reorganise it, a glass or an amorphous solid are typical quenched material.
2 At first sight, averaging the driving equation looks to be simpler, and would evidently provide the arithmetic average for the conductivity, a clearly wrong result.
3 Notice that in the current practice, the result of the evaluation of these formula, or of the numerical solution of the auxiliary problem is used to populate the coarse grid of 𝛺 blocks, using the underlying local fine grid data. So the equivalent Kequ may still depend on position rather than the so-called Keff that is intrinsic, it would correspond to working with an infinite volume 𝛺.
4 We implicitly consider that fully analytically solvable problems are very scarce!