

1 Introduction
In many biomedical applications, semi-quantitative or qualitative variables are observed, which are valued on a small number of levels (typically the integers from 0 to 10), but are comparable through a strategy of monotony testing. If only the succession of intervals of monotony of the function, between the times of observation (either discrete or continuous), is important for comparing these variables, we only consider the sequence of signs of these intervals (“+1”, if the function is increasing or constant, and “−1” if the function is decreasing) called the stochastic monotony signature, and then we calculate the probability that a sequence of signs is similar or not to another reference sequence. We will restrict the present study to the case where one cannot observe the same biological object at different times or locations on a one-dimensional scale, because it is experimentally destroyed, censored or individually hidden by a double blind procedure. Hence, it is observed a series of empirical distributions and the monotony intervals, bounded by observation times. The support of the empirical distributions is an interval in the uniform case and an estimate of the 95%-confidence interval in the Gaussian case.
A test will be built under the assumption of independence of the components and increments of the observed variables at the observation times which constitute the frontiers of the monotony intervals and we will present typical examples in four application domains: one will focus on the comparison of intervals of monotony of histograms corresponding to the observation of physiological events (crossing-overs), observed for men and women and compared on a single human chromosome. The second example concerns the answers of a group of individuals during double blinded exercises of choice of an image among a pair of images, along a succession of image pairs presented successively. The third example is related to the evolution during the nychthemeron (day/night 24 h interval) of the number of entrances in a given room, observed for different rooms and successive 25 days. The final example concerns microscopic data about segregation and transport of colloidal particles during microtubule morphogenesis, phenomena compared with and without gravity.
The former biomedical methodologies concerning monotony comparison are essentially coming from the LD50 toxicological bioassays, in which there is no individual horizontal sampling because the animals tested are not reused (because death or pathologic—even minor—reaction) after each dose administration. These bioassays produce data susceptible to benefit from a monotony signature testing, notably in their sequential version, in which the experimental procedure consists in choosing increasing toxic doses d1,…,dn, giving lethal effects X1,…,Xn (measured by the percentage of death) based on former experiments done on a known reference drug of the same chemical family giving lethal effects Y1,…,Yn, procedure called prediction and based on reference chemicals testing [1]. X1,…,Xn and Y1,…,Yn are considered as random variables observed at the same times.
The first attempt to compare the monotony intervals has been to use the rank statistics correlation test [2,3]. More precisely, if r(X) denotes the decreasing rank statistics of X, we have for the sign of the ith monotony interval of X, denoted sgnXi:
Hence, we have:
| (1) |
Let us suppose that X is a random vector with independent components and increments; then (1) becomes (2):
| (2) |
For example, if sgnX = (−1,…,−1), then we have:
P({sgnX = (–1,…,–1)}) = P(∩i = 1,…,n–1{Xi + 1 – Xi < 0}) = Πi = 1,…,n–1 P({Xi + 1 < Xi}) = Πi = 1,…,n–1 P(∪ξi∈S(fi) ({Xi = ξi}∩{Xi + 1 < ξi})) = Πi = 1,…,n–1 ʃS(fi) fi(ξi)Fi + 1(ξi) dξi.
The formulas above show that the knowledge about the rank statistics r(X) gives the monotony signature sgnX, but that the converse is false. Then, an identity test between sgnX and sgnY is possible when the monotony intervals are observed, even if the rank statistics remain unknown. We will build such a test in the following.
2 Stochastic monotony signature: definition and study of the distribution
2.1 Definitions
Let us consider the graphs of real functions of time, X(t) and Y(t), recorded at the same observation instants belonging to the discrete time set {t1,…tn}⊂ given in Fig. 1. We suppose that the studied phenomenon involves in general the censoring of the observed system (individual, cell, chromosome…) by loss, death, destruction… Hence, we only get from the experiments the empirical distribution of the data recorded on a sample of individuals different at each time (like in the LD50 experiments). We call monotony signature of X (resp. Y) the sequence of the values “+1” and “−1” corresponding to their successive monotony intervals: sgnXi = +1 (resp. −1) corresponds to the increase or constancy (resp. decrease) of the function X on its ith monotony interval, and the monotony signature of X (resp. Y) for nine successive intervals of monotony in Fig. 1 equals:{sgnXi}i = 1,9 = (+1,−1,+1,+1,−1,−1,+1,+1,−1) (resp. {sgnYi}i = 1,9 = (−1,−1,+1,+1,+1,−1,+1,+1,−1).
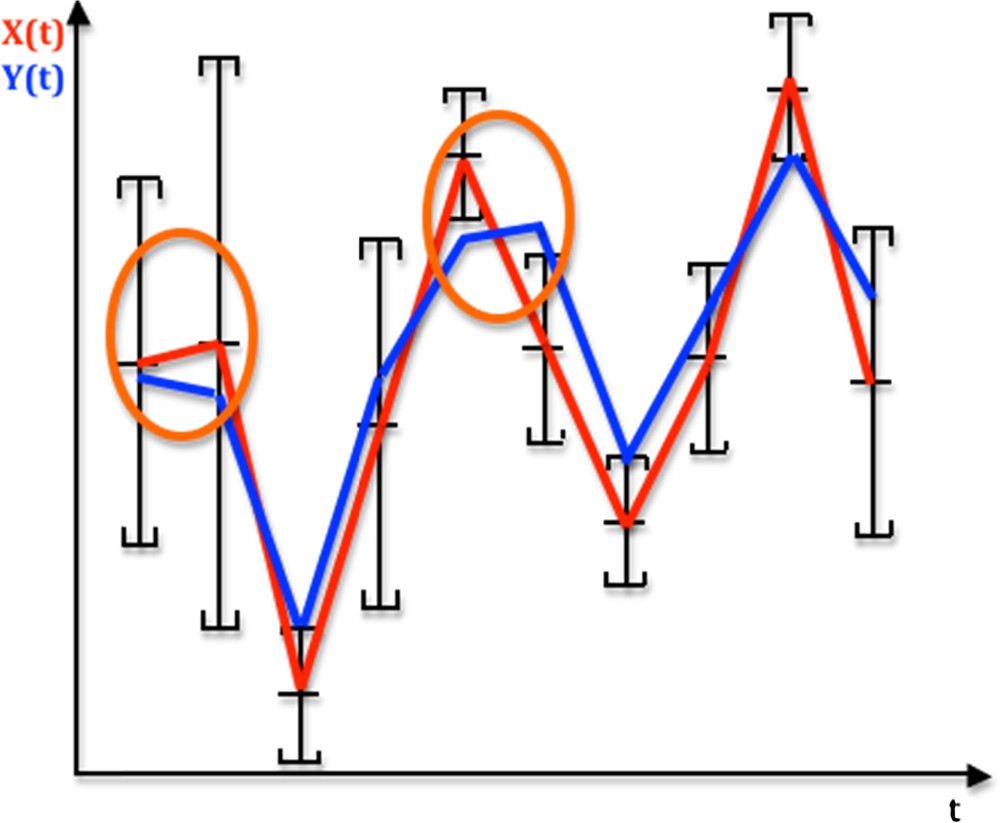
(Color online.) Temporal profiles of an observed signal X (red) and a reference signal Y (blue) over time t, indicating monotony segments between the successive averages of X, each average being the centre of the empirical 95% confidence interval of a distribution of errors on X supposed to be symmetrical. If it is supposed to be uniform, the weighted monotony signature of X is equal to (0.4,1,0,0,1,1,0,0,1). Monotony intervals circled in orange correspond to the difference between X and Y monotonies.
We can decide that the monotony signature of the observed X profile is significantly different from the Y reference profile (Fig. 1), after testing the similarity of these signatures due to a common causality between X and Y (hypothesis H1) against a random choice of the values of the successive sgnXi's (hypothesis H0), by using, when sgniY = −1, the probability P_i decreasing from a value taken on the support in (denoted above S(fi)) of the distribution fi of Xi to a value of Xi + 1 on S(fi + 1) (cf. Fig. 2 for i = 1):
| (3) |
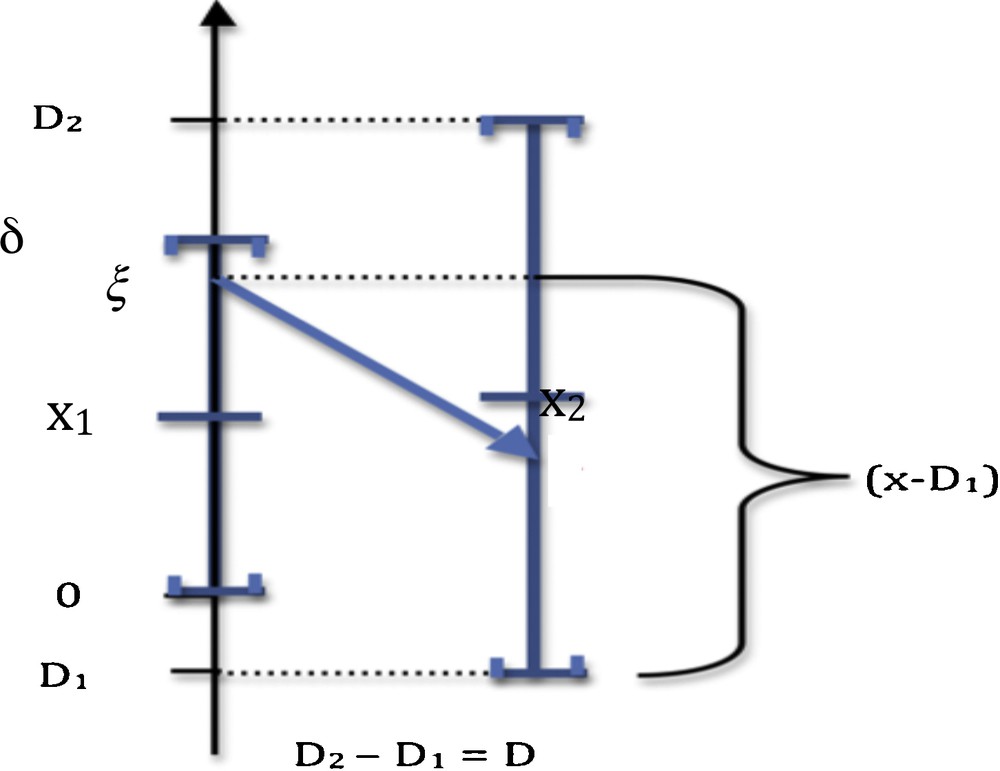
(Color online.) Calculation of the probability P_ of negative monotony, where [0,δ] (resp. [D1,D2]) and x1 (resp. X2) denote the interval and the mean of the uniform law of X1 (resp. X2).
The sequence of the probabilities {P_i}i = 1,…,n–1 of decay of X on its ith monotony interval is called the weighted monotony signature of X.
2.2 Gaussian errors
Proposition 1 In the Gaussian case, where the distribution of Xi is N(xi,σi), we have:
| (4) |
Proof 1 If the density distribution of errors is Gaussian, the formula (3) becomes (by neglecting the index i):
P_ = ʃIR f(ξ) F(aξ + b) dξ,
where f (resp. F) is the distribution (resp. cumulative distribution) function of the standard Gaussian law N(0,1), a = σ1/σ2 and b = (μ1 – μ2)/σ2. By changing the integration variable ξ in z = F(ax + b), we have:
dz = af(aξ + b) dξ and ξ = (g(z) – b)/a,
where g = F−1. Then we can write P_ under the following formula:
Because the cumulative distribution functions of the uniform law on [–2σ, 2σ] and of the Gaussian law N(0,σ) are very close (cf. Fig. 3, right), the results concerning the calculations of P_ are similar. Then, in any case of errors, we have chosen uniformly 100 couples of values (xi,xi + 1)i = 1,…,100 in [0,10]2. Then, we simulated 100 samples of 100 couples of values (ξik,ξ(i + 1)k)k = 1,…,100 by using 100 couples of Gaussian distributions {N(xi,1), N(xi + 1,1)}i = 1,…,100, and we calculated the difference Δi between the probability P_i calculated from the integral formula (1) and the empirical frequency P_i* obtained from the observation of the events {ξik > ξ (i + 1)k}k = 1,…,100. The result is given in Fig. 3 (left), showing as expected that the empirical distribution fΔ* of the random variable Δi = P_i – P_i* is asymptotically (in sample size) Gaussian N(0,1).
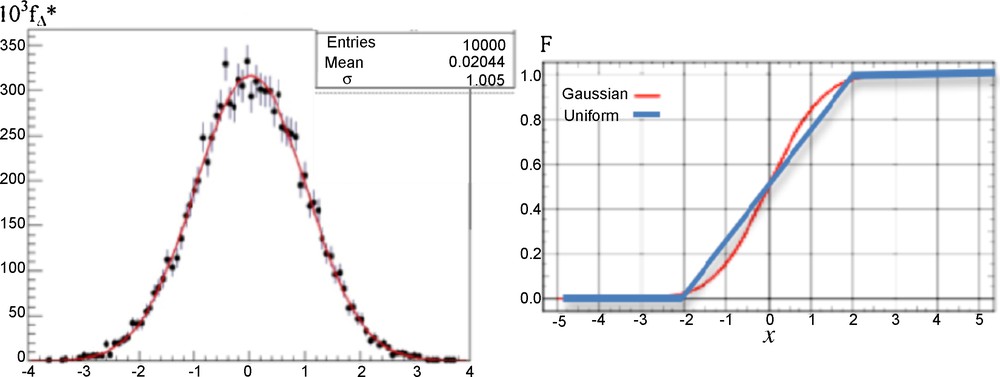
(Color online.) Left: empirical distribution fΔ* of the random variable Δ = P_–P_*, asymptotically (in sample size) Gaussian N(0,1) (red curve). Right: theoretical cumulative function F of the uniform (blue) and Gaussian (red) distributions of errors.
2.3 Uniform errors
Proposition 2 In the uniform case, let denote by [0,δ] (resp. [D1,D2]) and x1 (resp. x2) the interval and the mean of the uniform law of X1 (resp. X2). Then, there are six different configurations (cf. Fig. 4):
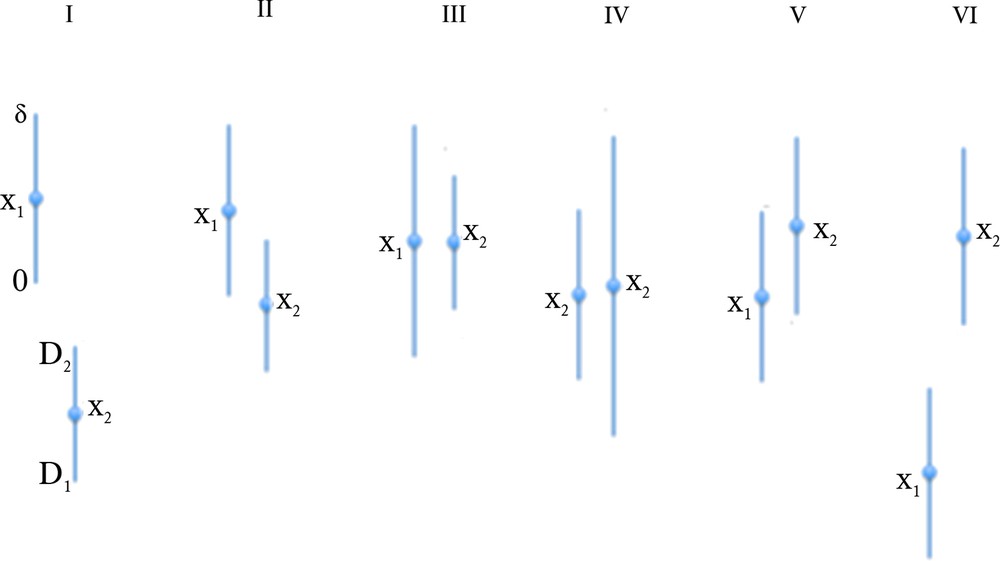
(Color online.) The six different configurations of X1 and X2 supports in the case of the uniform distributions of errors.
1) D1 < 0 ≤ δ ≤ D2, then P_ = [(δ – D1)2 – D12]/2δD = δ/2D – D1/D I
2) D1 < 0 ≤ D2 < δ, then P_ = 1 – D22/2δD II
| (5) |
4) 0 ≤ D1 ≤ D2 < δ, then P_ = 1-(D22-D12)/2δD = (2δ-(D2 + D1))/2δ IV
5) D1 > δ, then P_ = 0 V
6) D2 < 0, then P_ = 1 VI
Proof 2 In the uniform case, the formula (3) becomes:
Hence, we have:
inf(δ,D2)
inf(δ,D2)
Then, by considering all the possibilities of values of the extrema inf(δ,D2) and sup(0,D1), we get the six different formulas (5) (cf. Fig. 4) ■
3 A statistical test of monotony
We will suppose in the following that the distribution function of Xi is uniform on [ai1,ai2] and that X is a stochastic process with independent components and increments. In Fig. 1, the probability P_ of decay of X is equal to 0.4 for the first interval of monotony and 1 for the fifth (both circled in orange). P_ equals also 1 for the second, sixth and ninth intervals, and 0 for the third, fourth, seventh and eighth ones. Let us denote by P(η) the probability of having η differences between the signs of monotony of observed X(t) and reference Y(t) signals. We call H0 the hypothesis saying that monotony signatures of X and Y are similar by chance with independency between X and Y, the probabilistic structure being defined by the empirical estimates of their distributions and the independency of the components and increments of X.
Then, if η = 2, the probability P(2) under the hypothesis H0 equals:
| (6) |
- • in the case where sgnY is deterministic, P≠i = P_i if sgnYi = +1 and P≠i = 1–P_i if sgnYi = –1;
- • in the case where sgnY is random and independent of sgnX: P≠i = P_i(X)(1–P_i(Y)) + (1–P_i(X))P_i(Y), where P_i(X) denotes the probability that X decreases on its ith monotony interval.
In the case of Fig. 1, we have, by supposing the successive monotony signs of Y known with a certainty of 3/4:
| (7) |
We can therefore consider that the probability of rejecting falsely the hypothesis that monotony similarity, except for η = 2 intervals, is due to chance with independency between X and Y is less than 5%. This test is not as powerful as a correlation test, but it is interesting in the case of a low number of longitudinal observations in which signal amplitude is not pertinent compared to monotony, when the variance of the empirical correlation with a reference signal is important. Easy calculations above require that reference Y and observed signal X are known at the same instants of observation and random process X(t) has independent components and increments. The cause of rejecting the hypothesis of similarity with independency between X and Y is the presence of a link between successive values of the observed and reference signals.
4 Biomedical applications
We will give in the following simple illustrative examples where monotony signature is pertinent.
4.1 Genetic events localization
Fig. 5 below gives the localization X (resp. Y) of the physiologic crossing-overs along chromosome 3 for human females, with the blue curve in Fig. 5 (resp. males, with red bars) [4]. By comparing the two monotony signatures as given, we reject the hypothesis that female and male crossing-overs have similar localization by chance with independency between X and Y (P < 10−7), which is in favor of the existence of the same frailty domains along the male and female chromosome, explaining the frequency of crossing-over co-occurrences.
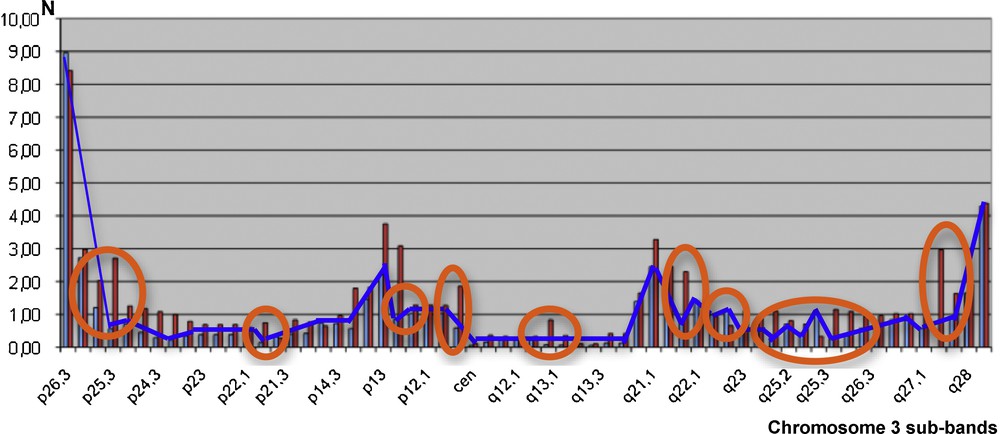
(Color online.) Crossing-over numbers N (male red bars and female blue curve) along the human chromosome 3 (12/63 monotonic discrepancies encircled by orange ellipses).
4.2 Individual choices and collective consciousness
During successive sessions of choice, participants belonging to a defined group are choosing one picture from an “absurd questionnaire” consisting of 50 pairs of pictures, in each of which one picture has to be chosen [5]. The results given in Fig. 6 are used to search for evidence in favor of the influence of group dynamics on individual choices of the pictures proposed in the questionnaire. The swaps between the two pictures of a pair, measured for each pair of pictures between the initial choice (called A choice) across sessions could be interpreted as a manifestation of group dynamics: for instance, the “honeymoon” (dependence on the leader) and the successive “fight-flight” (reaction against the dependence on the leader) attitudes could be represented by a greater number of group dynamics swaps (further away from pure randomness). It seems intuitive that an increase of simultaneous swaps could be linked to an increased group activity or group dynamics event. Statistics carried out on the totality of swaps A→B or B→A evidenced a significant increase in the swap numbers between S01/S02 and S02/S03 session transitions, and between S03/S04 and S04/S05 session transitions, incompatible with a random fluctuation. In other words, the number of changes in choices increased significantly between the 1st and the 3rd sessions, and then remained essentially constant until the end of the training, except between the 3rd and the 5th sessions. During session S04, the number X of A→B swaps and Y of B→A swaps showed similar fluctuations close to significance against similarity obtained by chance with independency between X and Y (P = 0.6), while there is no significant change in the evolution of the sum X + Y. This is consistent with the existence of a collective unconscious behavior.
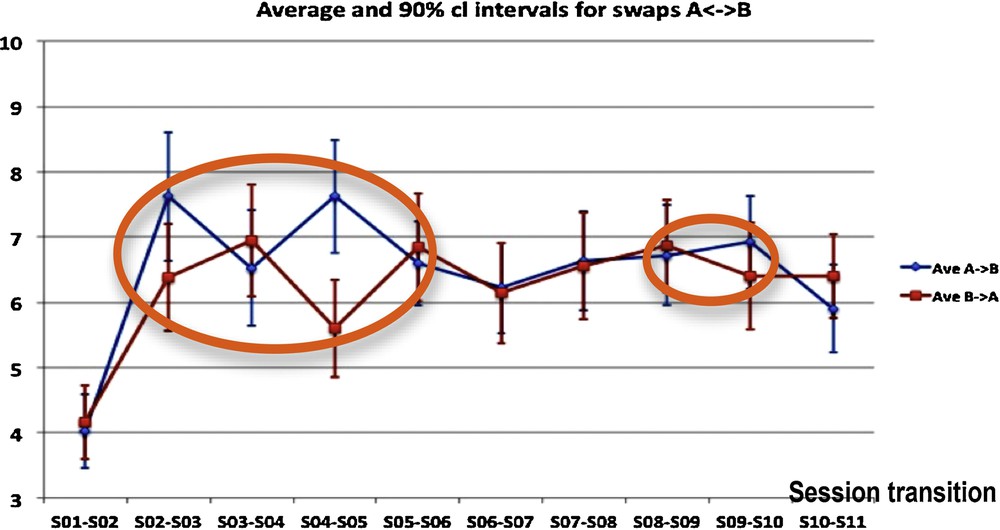
(Color online.) Group dynamics-driven swaps from picture A to B and from picture B to A, occurring over time between 11 consecutive sessions for each of 50 pairs of pictures, for the two types of swaps (A to B and B to A). We see inside orange ellipses the localization of discrepancies between the monotony of the curves relative to A→B and B→A swap numbers.
4.3 Actimetry
After 25 days of observation of a person at home [6–8], we get the results given in Fig. 7 corresponding to his/her staying in the different rooms of a smart flat in which different sensors recorded his/her activity at home. They allow us to calculate different temporal profiles assigning the observed person in different clusters corresponding to a normal or a pathologic behavior. Alarms can be triggered when passing from a normal type of nychthemeral activity to a pathologic one. For example, in a degenerative neural pathology like Alzheimer's disease, we can observe an abnormal activity in the same room, called perseveration, which is a pathologic repetition of actions in general already successful (“errare humanum est, perseverare diabolicum”) [9]. We model this phenomenon of persistence in a pathologic activity by setting atypical extended occupancy periods in a room or by performing repetitively a specific daily routine, in comparison to more standard scenarios encountered in everyday life.
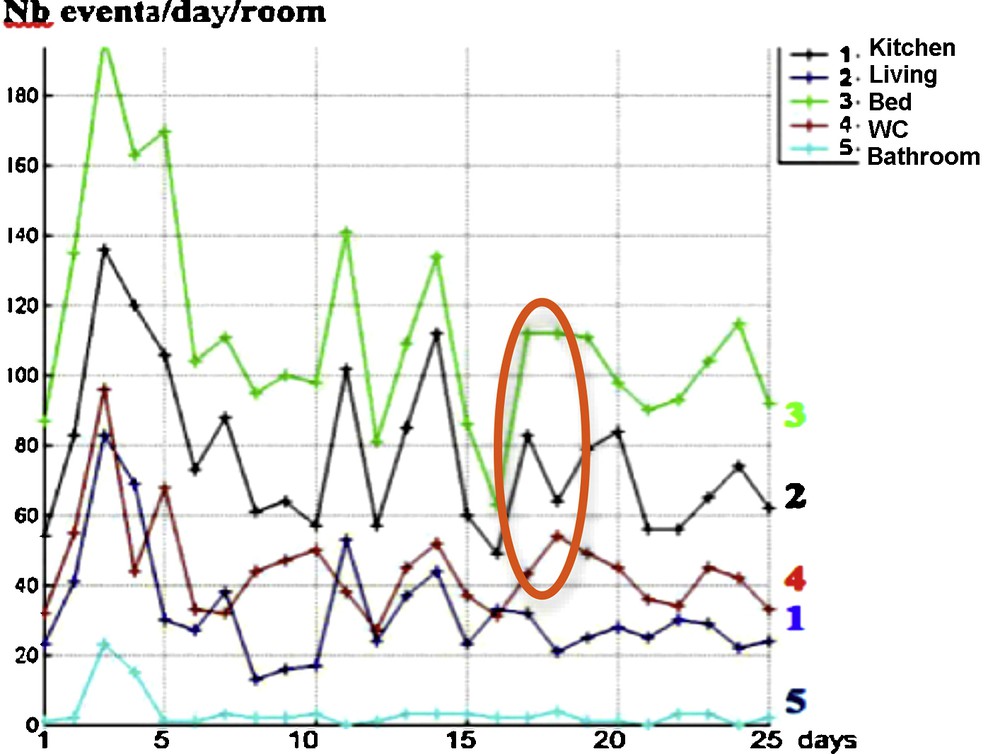
(Color online.) Evolution during the nychthemeron (day/night 24-h interval) of the number of entrances in room, for different rooms, during 25 successive days. We see in orange the localization of the monotony dissimilarities between curves No. 3 (number of entrances in bedroom) and No. 4 (number of entrances in the toilets).
A way to compare different temporal evolutions of room occupancies is to follow the evolution in time of the number of events of entrance in room, for different rooms and 25 successive days. The fluidity of the activity can be related to the number of entrances in connected rooms like the bedroom and the toilets, because a decorrelation between these numbers could sign a stereotyped activity by repeating for example pathological entrances in the toilets or non-entrances from the bedroom (e.g., in case of anuria, nocturia, or pollakiuria). The data in Fig. 7 show that only three discrepancies within a period of 25 days allow us to reject a similarity between entrance activities No. 3 and No. 4 by chance, with independency of these activities (P = 2 × 10−7), the same monotony signature for connected rooms being then the sign of a normal behavior.
4.4 Microtubule morphogenesis
In [9,10], the authors recall that weightlessness is known to affect cellular functions by as yet undetermined processes, but with a role of the cytoskeleton and microtubules, which behave as a complex system that self-organizes by a combination of reaction, diffusion, collective transport and self-organization of any present colloidal particles [9]. This self-organization does not occur when samples are exposed to a brief early period of weightlessness [10]. During both space-flight and ground-based (clino-rotation) experiments on the effect of weightlessness on the transport and segregation of colloidal particles, a significant difference between the velocity of colloidal particle beads has been observed (Fig. 8), as well as the rejection of the similarity by chance with independency between gravity and non-gravity monotony signatures during the evolution of the microtubule organization in embryonic cells (P = 3 × 10−5). This suggests, depending on factors such as cell and embryo shapes, that major biological functions associated with microtubule-driven particle transport and self-organization might be strongly perturbed in velocity amplitude, but not in sequencing, by weightlessness.
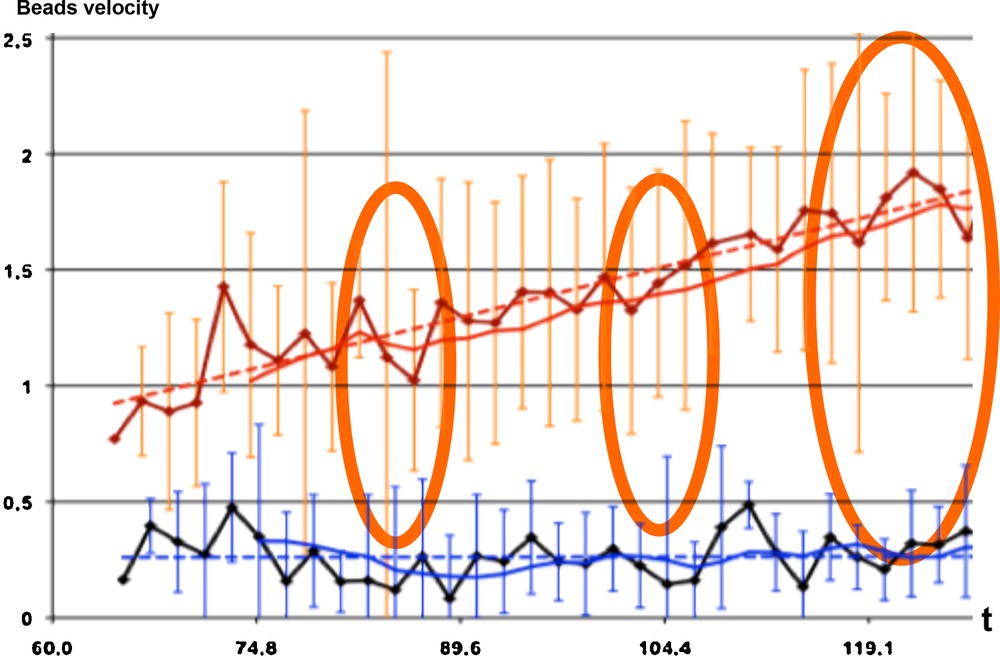
(Color online.) Evolution during 60 s of the observed number of beads in the cell preparation, showing 4/30 discrepancies (orange ellipses) between the bead numbers observed under a gravity field (1G for the red curves) and in the absence of gravity (black and blue curves).
5 Conclusion
The stochastic signature of monotony and the associated statistical test of similarity of monotony allow us to manage situations in which two signals have to be compared, not in amplitude, but only through the succession of their monotony intervals. Numerous situations in which this approach can be used exist in biology, and we have selected four cases in biomedicine, in which the present tool seems to be pertinent.
If there exists an empirical correlation between two successive increments, then the test must be done with a reference signature provided with this correlation structure estimated from the empirical law. It is the case if the process is observed through a longitudinal sampling of individual histories, even if the process has independent components. More, if the components are not independent, but if it is possible to calculate the joint empirical distribution of the signs of monotony signature for each individual history, provided it makes sense at the observation level (time sampling allowing the estimation of the non-Markovian dependence of the increments), and if we know the distribution of the reference signature, then the test to be used is an identity test between reference and empirical distributions. This situation will be studied in a future article.
Disclosure of interest
The authors declare that they have no competing interest.
Acknowledgements
We are very indebted to Yannick Kergosien for his helpful suggestions and exciting discussions.