

Version française abrégée
L'épidémiologie des cancers a connu un essor important à partir des années 1950. L'un de ses apports les plus spectaculaires et les plus spécifiques a été la mise en évidence de l'effet massif de la consommation de tabac, avec un temps de latence important, sur la survenue des cancers du poumon, du larynx et de la vessie. Des carcinogènes majeurs, nombreux et de nature variée, ont été identifiés dans l'environnement de travail (fibres d'amiante, métaux lourds, suies et goudrons, arsenic, benzène, amines aromatiques, monochlorure de vinyle, radiations ionisantes) comme dans l'environnement général (radon résidentiel, UV, aflatoxines). Plusieurs variétés de virus (EBV, HPV, HBC, HCV, HTLV1, HHV8...) se sont révélées cancérogènes, de même que des bactéries (Helicobacter pylori) et des parasites (bilharzie). Certains cancérogènes majeurs sont d'origine iatrogène, en particulier les traitements anticancéreux (radiations ionisantes, alkylants, épipodophyllotoxines) ou, à un moindre degré, certains traitements hormonaux. Jusqu'à présent, en dehors de la consommation d'alcool dans les cancers de l'œsophage, des voies aéro-digestives supérieures (VADS) et du foie, peu de facteurs liés à l'alimentation ont fait la preuve de leur cancérogénicité. Les expositions environnementales et les comportements possiblement ou probablement cancérogènes d'après la somme des recherches antérieures constituent une très longue liste, qui se clarifie progressivement. En parallèle des avancées sur les cancérogènes environnementaux, des progrès considérables ont permis de comprendre certains cancers héréditaires dus à des délétions transmissibles de gènes suppresseurs de tumeurs, comme le gène Rb dans le rétinoblastome ou le gène TP53 dans le syndrome de Li et Fraumeni, qui sont des gènes-clé du cycle cellulaire et de l'apoptose, ou les gènes BRCA1 et BRCA2 dans le cancer du sein ou MSH2 et MLH1 dans le cancer du côlon non polypoïde, qui sont des gènes de la réparation de l'ADN impliqués dans le maintien de l'intégrité du génome. Il existe encore peu d'exemples dans lesquels des interactions entre prédisposition héréditaire au cancer et facteurs environnementaux ont été identifiées. C'est le cas dans le Xeroderma pigmentosum, où des anomalies des gènes XP empêchent la réparation des lésions de l'ADN induites par les UV, ce qui conduit à la transformation maligne des cellules cutanées.
Les modèles classiques de cancérogenèse supposent l'existence de plusieurs événements mutationnels successifs sur un même clone cellulaire, qui le font progressivement échapper aux mécanismes assurant la régulation de la division cellulaire et le maintien de l'intégrité du génome. La chaîne d'événements qui conduit d'une exposition environnementale au cancer fait potentiellement intervenir des centaines de gènes polymorphes codant pour des protéines impliquées, soit dans le transport et le métabolisme des xénobiotiques, soit dans la réparation, soit encore dans la réponse immunitaire ou l'inflammation, avec des fréquences d'allèles variants suffisantes pour que l'on puisse envisager de contraster des groupes de sujets ayant des prédispositions différentes au cancer en cas d'exposition. D'autres gènes, également polymorphes, peuvent intervenir dans la propension individuelle à développer un cancer dans certaines conditions d'exposition (gènes de la pigmentation, gènes des récepteurs hormonaux...). Les caractères multifactoriel et multi-étape du cancer créent des conditions théoriques d'interaction statistique, puisque certains facteurs interviennent à des étapes complémentaires du processus cancéreux. La réalité est que ces interactions ne sont visibles que si les associations sont assez fortes, que les expositions sont bien mesurées en considérant des périodes d'exposition pertinentes, et que la multiplicité des facteurs n'est pas trop importante. De fait, la recherche d'une interaction statistique entre exposition et gènes dans les cancers s'est généralement révélée infructueuse, malgré l'exemple inaugural confirmé de l'interaction entre NAT2 et amines aromatiques dans le cancer de la vessie.
Les deux dernières décennies ont produit une masse très importante de données, pour la plupart en suivant une approche gène candidat, ciblant les polymorphismes connus situés dans un nombre limité de gènes. Des consortiums internationaux ont permis de réunir des effectifs de grande taille pour étudier des associations faibles et s'intéresser à des sous-groupes de cancer ou à des expositions rares. Plusieurs exemples de ces travaux sont présentés. Les publications les plus nombreuses concernent les interactions entre la consommation de tabac et les gènes des enzymes impliquées dans le métabolisme des xénobiotiques dans les cancers du poumon, de la vessie et des VADS. En effet, il s'agit de cancers fréquents, d'expositions prévalentes et assez facilement quantifiées, et les expositions aux hydrocarbures polycycliques aromatiques, aux nitrosamines et aux amines aromatiques générées par la consommation de tabac suivent des schémas métaboliques de mieux en mieux identifiés. Il existe, de plus, dans le cancer du poumon une composante familiale faible, mais décelable, qui contribue à accréditer l'idée d'une inégalité constitutionnelle vis-à-vis du cancer à exposition identique. Les gènes impliqués dans les mécanismes de réparation de l'ADN sont également de plus en plus étudiés dans ces cancers liés aux radiations et au tabac. L'étude des interactions gènes–environnement concernant les autres types de cancers et/ou d'autres expositions environnementales a dans l'ensemble moins de recul.
L'un des enseignements, prévisible, de ces années d'investigation, est que l'étude des interactions gènes–environnement nécessite un effort important sur l'évaluation des expositions environnementales si l'on veut qu'elle contribue à améliorer la détection des faibles risques relatifs. Jusqu'à présent, à notre connaissance, aucun facteur de risque environnemental de cancer n'a été révélé par la prise en compte d'un génotype de susceptibilité. Un autre enseignement est la remise en cause progressive de la notion de gène candidat. Le nombre élevé des polymorphismes candidats par fonction tempère de fait l'opposition entre une démarche de type génération d'hypothèses par screening versus test d'hypothèse d'un gène particulier. Classiquement, la première serait une pêche à la ligne improductive, alors que la seconde est supposée intelligente et productive. Les gènes candidats, déjà multiples, ne sont probablement qu'une partie des gènes que l'on pourra considérer comme candidats dans quelques mois ou années. Même en limitant notre intérêt aux gènes candidats, on ne peut plus échapper à la problématique des tests multiples, et que l'on choisisse cette approche ou l'approche génome entier, le développement de méthodes aidant à extraire de l'information du bruit au sein des données issues des plateformes de génotypage à haut débit constitue un enjeu majeur.
En conclusion, les cancers résultent de processus complexes, qui font intervenir des gènes et des facteurs environnementaux, avec de multiples interactions entre polymorphismes génétiques, entre facteurs environnementaux et entre polymorphismes génétiques et facteurs environnementaux. C'est un constat et l'on ne peut pas échapper à cette complexité, que les prochaines années nous aideront à mieux déchiffrer. Les outils se mettent en place : nos enquêtes ont su se doter de collections biologiques bien échantillonnées, des plateformes de génotypage à haut débit deviennent accessibles, les travaux de méthodologie statistiques se développent, les bases bioinformatiques s'étoffent et leur accès se clarifie, les consortiums internationaux s'organisent. La compréhension du rôle des facteurs environnementaux avance conjointement à celle des facteurs génétiques. Les règles de base de l'épidémiologie, exigeantes à la fois sur l'échantillonnage et les critères histologiques et moléculaires de classement du cancer, sur l'évaluation des expositions environnementales, leur temporalité, leur quantification et leurs covariables, sur la taille des enquêtes et sur la rigueur des analyses multivariées, sont plus que jamais d'actualité.
1 Introduction
1.1 Environment and cancer
Cancer epidemiology has undergone marked development since the 1950s. One of the most spectacular and specific contributions was the demonstration of the massive effect of smoking, with a long lag time, on the occurrence of lung, larynx, and bladder cancer. Major carcinogens, numerous and of varied natures, have been identified in the working environment (asbestos fibres, heavy metals, soot and tar, arsenic, benzene, aromatic amines, vinyl monochloride, ionizing radiation, etc.), and in the overall environment (residential radon, UV radiation, aflatoxin). Several viruses (EBV, HPV, HBV, HCV, HTLV1, HHV8, etc.) have been shown to be carcinogenic, as are some bacteria (Helicobacter pylori) and parasites (Schistosoma). Certain major carcinogens are of iatrogenic origin, in particular cancer treatments (ionizing radiations, alkylating agents, epipodophyllotoxin), as are, to a lesser degree, some hormone treatments. To date, apart from alcohol intake with respect to oesophagal, upper aerodigestive tract, and liver cancer, few diet-related factors have been shown to be carcinogenic.
Factors influencing the occurrence of cancer without being directly carcinogenic have frequently been evidenced before the underlying cause was revealed. Thus, the influence of sexual relationships with multiple partners on cervical cancer was known long before the papilloma virus was implicated. Similarly, the role of the mode of food storage on stomach cancer was elucidated before the role of Helicobacter pylori was discovered. A certain number of dietary behaviour patterns, a sedentary lifestyle, and excess weight are currently known to be associated with the risk of various types of cancer, without their role in carcinogenesis having been clearly elucidated.
Generally speaking, environmental exposures and behaviour patterns that may be considered possibly or probably carcinogenic based on the sum of previous researches constitute a very long list. But the list drawn up 20 years ago has been markedly clarified, first, because our know-how has improved (better designs, better questionnaires, large-scale studies, better analytical instruments) and, secondly, because we have gradually benefited from concomitant technological progress. The availability of sensitive and reliable dosimeters contributed to establishing the association between domestic radon and lung cancer; the existence of viral genome markers enabled demonstration of the involvement of HPV in cervical cancer and EBV in certain Hodgkin's lymphomas; laboratory exposure markers have confirmed the association between aflatoxin and hepatic carcinoma. The same techniques will doubtless bring new contributions in the coming years.
Research on the environment and cancer has led to cancer being modelled as a multistage process during which the cell genome undergoes a succession of changes that are sufficient for the cell to escape from its control mechanisms, but insufficient for it not to survive. Little by little, biological research has elucidated the main biological pathways through which a cell becomes malignant, the multiple factors involved, their interactions and, frequently, their pleiotropic nature. Recent concepts such as epigenetics and the role of micro-RNA in the regulation of gene expression will probably further modify our view of the role of the environment in the occurrence of cancer.
1.2 Heredity and cancer
In parallel, considerable progress has enabled elucidation of certain hereditary cancers due to inherited deletions of tumour-suppressor genes, such as gene Rb in retinoblastoma and gene TP53 in the Li–Fraumeni syndrome. The latter are key genes in the cell cycle and apoptosis. Further examples include genes BRCA1 and BRCA2 in breast cancer, and MSH2 and MLH1 in non-polypoid colonic cancer. These genes are DNA repair genes involved in maintaining the integrity of the genome. Few examples of interactions between a hereditary predisposition to cancer and environmental factors have so far been identified. However, in Xeroderma pigmentosum, anomalies of genes XP prevent the repair of UV-radiation-induced DNA lesions, resulting in the malignant transformation of skin cells.
1.3 ‘-omics’
Study of the transcriptome has undergone an explosive development over the last decade. The aetiological research value is not yet clear, but may become so through the introduction of tumour classifications that are more functional than histological and by revealing potential sources of between-individual response variability that could play a role before the tumour develops, during the cancerization process.
Study of the tumour genomic map in cancers of multifactorial origin has also raised the hope of evidencing specific signatures for particular exposures (e.g., mutations of gene RET and ionizing radiation in thyroid cancer), or a sort of molecular synopsis of the pathways of cell cancerization (e.g., pathways TP53, RB1, CDKN2A, etc.), and distinguishing subjects who are genetically predisposed to a given response. Currently, to the author's knowledge, those studies have not yet shown gene–environment interactions.
1.4 Gene–environment interactions: the biological viewpoint
Cancers are chronic multifactorial diseases whose genesis occurs at a variable rate. For example, leukaemia induced by epipodophyllotoxin treatment may develop in six months, while the lag time for asbestos-related pleural mesothelioma emergence is of the order of 40 years.
The conventional models used to describe carcinogenesis suppose the existence of several successive mutation events affecting a given cell clone and inducing its gradual escape from the mechanisms ensuring regulation of cell division and maintenance of genomic integrity (Fig. 1). Neighbouring cells also exert a direct or indirect influence on the process. According to those models, the greater is the number of stages, the greater is the age of onset. The earlier a carcinogen intervenes in the process, the greater is the tumour induction time (and hence lag time). In the chain of events from exposure to cancer, the chemical agent is transported and metabolized by a set of proteins. In most of the models of chemical carcinogenesis, the exposure, or more generally the metabolites, interacts with DNA, forming adducts that, if not eliminated, induce DNA mutation at their binding sites. Ionizing radiation, ultraviolet radiation, and alkylating agents elicit different DNA repair pathways, while carcinogenesis with an infectious aetiology elicits different immune response genes. Hundreds of genes coding for proteins involved in the transport and metabolism of xenobiotics, or in repair, or in an immune or inflammatory response are polymorphic, with variant allele frequencies sufficient for it to be possible to envisage contrasting groups of subjects with different predispositions to cancer in the event of exposure. In addition to those polymorphisms, there are other categories of genes that may intervene in the individual propensity to develop a cancer under certain exposure conditions (pigmentation genes, hormone-receptor genes, etc.).
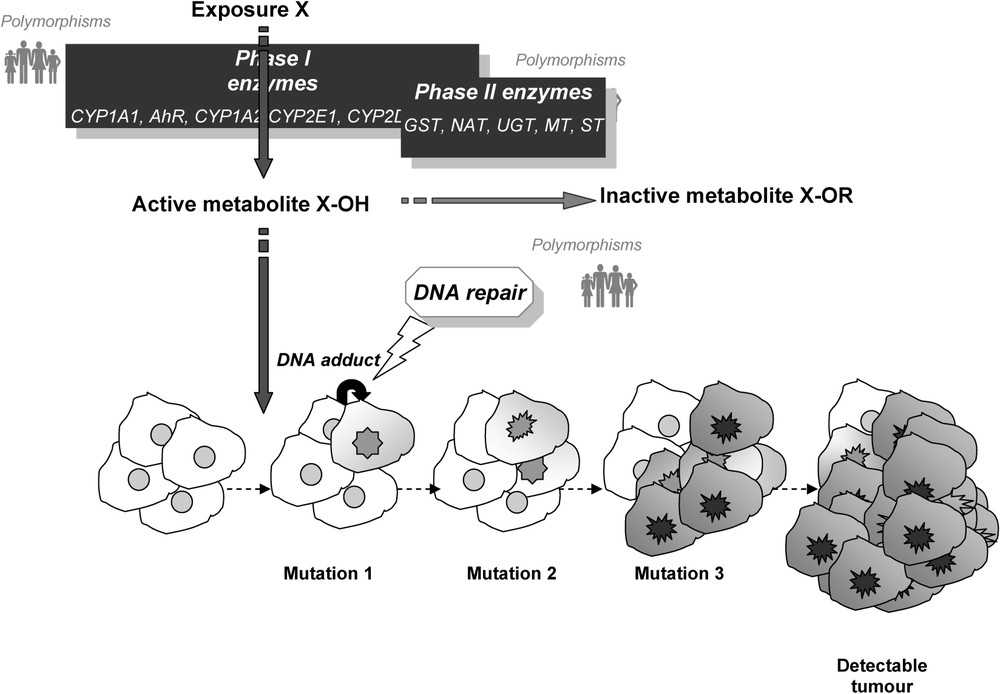
Simplified diagram of the chemical carcinogenesis model.
There is no escape from the complexity revealed by awareness of the array of polymorphisms, but we may attempt to manage that complexity. Many studies aim to identify the sensitivity profiles for specific carcinogens by considering all the genes involved in the body's management of a given physical, chemical, or biological agent.
These designs will probably be amended when we are able to incorporate the epigenetic mechanisms enabling response to the external environment and to potential carcinogens, not just at cell or even body level, but at the scale of a population.
1.5 Gene–environment interactions: the statistical and epidemiological viewpoint
The biological interaction between the environment and the genome of a cell of an individual may exceptionally be reflected in statistical interactions that can be detected at the population level. This is not surprising, given the number and diversity of the parameters. In fact, the complexity of environmental exposures is additional to the complexity of the genetic predisposing factors cited above. Environmental exposure frequently consists in exposure to a mixture of potential carcinogens (e.g., smoking, paint, pesticides, and air pollution), and various exposures are associated for a given individual, concomitantly or serially. The multifactorial and multistage characteristics of cancer create the theoretical conditions for statistical interaction. The cancer risk associated with early exposure to a carcinogen depends on the subsequent exposures of the impaired cell to carcinogens, inducing pursuit of cell transformation. Conversely, the risk associated with carcinogen exposure at a late stage in carcinogenesis depends on the completion or non-completion of the previous carcinogenetic stages. The non-independence of the exposures occurring at complementary stages in the process should theoretically result in a statistical interaction. The relative risk for the joint effect of the exposures is then greater than the multiplication of the relative risks estimating the effects of each exposure. In reality, the interactions are only visible if the associations are fairly strong, the exposures are correctly measured during pertinent exposure periods, and the multiplicity of factors is not too great. In fact, investigation for a statistical interaction between exposure and genes in cancer has generally proved fruitless, despite the confirmed inaugural example of the interaction between NAT2 and aromatic amines in bladder cancer [1].
Research on gene–environment interactions in cancer increasingly means studying the joint effects of genes and environmental exposures. Research has even been extended, in a certain manner, to investigating the specific effect of polymorphisms in diseases strongly related to a particular exposure. Thus, the study of the role of polymorphisms of genes coding for the enzymes metabolizing benzo[a]pyrene in smoking-related cancers such as lung cancer is frequently presented as the study of gene–environment interactions.
2 Data on gene–environment interactions in cancer
Over the last two decades, a considerable mass of data has been generated. Most of the data were obtained using a candidate-gene approach targeting known polymorphisms situated in a limited number of genes. Very logically, the most numerous publications address the interactions between smoking and xenobiotic-metabolizing enzymes (XMEs) in lung cancer, bladder cancer, and cancer of the upper aerodigestive tract. These are frequent cancers, the exposures are prevalent and relatively easily qualified, and the exposures to aromatic polycyclic hydrocarbons, nitrosamines, and aromatic amines generated by smoking follow metabolic pathways that are increasingly well known. In addition, in lung cancer, there is a familial component that is weak, but detectable, and has contributed to accrediting the idea of a constitutional inequality with respect to cancer for a given exposure level. Obviously, smoking is also typically a mixture of chronic exposures accompanied by varied co-exposures and excessively simple designs obligatorily yield disappointing results. XMEs intervene in a major manner and some of their polymorphisms are relatively prevalent and markedly modify their effects. The polymorphisms of XME genes are naturally candidates for modulation of the clearly established relationship between cancers and complex chemical exposures. However, the redundancy of the pathways in which XMEs are involved may reduce the impact of those polymorphisms. The genes involved in DNA repair mechanisms are also being increasingly studied in cancers related to radiation and smoking. Less experience has been accumulated in the study of gene–environment interactions for other types of cancer and/or other environmental exposures.
2.1 Xenobiotic-metabolizing enzyme genes
The international Genetic Susceptibility to Environmental Carcinogenesis (GSEC) group [2] retrospectively pooled the data generated by the contributors to 152 studies: about 24 000 cases of different cancers and 28 000 controls. The analyses of the pooled data enabled indispensable synthetic findings, but nonetheless showed certain limitations, inconsistencies and sources of bias, which were amplified by the scale. In addition, several meta-analyses contributed to further elucidation. The results for CYP1A1, GSTM1, and NAT2 clearly illustrate the issue as a whole.
2.1.1 Smoking, benzopyrene and CYP1A1 and GSTM1 polymorphisms
Benzopyrene is a combustion product present, in particular, in cigarette smoke, exhaust fumes, as well as in soot and tar. Benzopyrene metabolism particularly involves the enzymes P4501A1 and GSTM1. With marked simplification, it may be considered that the former intervenes in phase 1, yielding a diol epoxide able to bind to DNA to form adducts, while the latter intervenes in phase 2, detoxifying the oxygen derivatives. The polymorphisms of the genes for those enzymes have a variable distribution depending on race. The frequency of allele CYP1A1*2A, which increases the activity of the enzyme, was estimated to be 6, 15 and 22% in Caucasians, Asians and Africans, respectively, while the frequency of GSTM1 deletion was estimated to be 53% for Caucasians and Asians and 27% for Africans [3].
Table 1 summarizes the results of the recent meta-analyses and pooled analyses of the relationships between those polymorphisms and the three smoking-related cancers. Overall, GSTM1 deletion appears to be associated with the three disease sites and the association is stronger for Asians. The raw results for CYP1A1 are more Table 1, the possibility of a link between CYP1A1 polymorphisms and lung and upper aerodigestive tract cancers cannot be ruled out.
Published meta-analyses and pooled analyses on the association between CYP1A1 (msp1) and GSTM1 null and smoking-related cancers (adjusted for age, gender and study)
| CYP1A1 | GSTM1 (null vs. present) | NAT2 3 | |||||||||||
| Caucasian | Asian | Caucasian | Asian | Caucasian | Asian | ||||||||
| OR | 95% CI | OR | 95% CI | OR | 95% CI | OR | 95% CI | OR | 95% CI | OR | 95% CI | ||
| Lung cancer | |||||||||||||
| [17] | 2451 cases | 2.4 | [1.2–4.8] | 1.1 | [0.8–1.7] | ||||||||
| 22 pooled studies1 (GSEC) | 3358 controls | ||||||||||||
| [4] | 1950 cases | 1.3 | [0.4–4.7] | 1.4 | [0.8–2.4] | ||||||||
| 11 pooled studies2 (GSEC) | 2617 controls | ||||||||||||
| [18] | 3940 cases | 1.0 | [0.9–1.1] | 1.1 | [0.8–1.5] | ||||||||
| 21 pooled studies (GSEC) | 5515 controls | ||||||||||||
| [18] | 7463 cases | 1.1 | [1.0–1.2] | 1.3 | [1.1–1.7] | ||||||||
| Meta-analysis – 43 studies | 10 789 controls | ||||||||||||
| [19] | 19 729 cases | 1.0 | [1.0–1.1] | 1.5 | [1.4–1.5] | ||||||||
| Meta-analysis – 119 studies | 25 931 controls | ||||||||||||
| Upper aerodigestive tract cancers | |||||||||||||
| [15] | 2334 cases | 1.0 | [0.6–1.4] | 1.2 | [0.9–1.5] | ||||||||
| 11 pooled studies (GSEC) | 2766 controls | ||||||||||||
| [15] | 4635 cases | 1.1 | [0.8–1.5] | 1.7 | [0.9–3.2] | 1.0 | [0.9–1.1] | 1.6 | [1.2–2.1] | ||||
| Meta-analysis – 30 studies | 5770 controls | ||||||||||||
| Bladder cancer | |||||||||||||
| [17] | 1530 cases | 1.4 | [1.1–1.8] | ||||||||||
| 8 pooled studies (GSEC) | 731 controls | ||||||||||||
| [20] | 1935 cases | 1.3 | [1.1–1.6] | 1.7 | [1.2–2.4] | ||||||||
| 17 pooled studies (GSEC) | 1444 controls | ||||||||||||
| [16] | 5091 cases | 1.4 | [1.2–1.6] | 1.4 | [1.2–1.6] | 1.4 | [1.3–1.5] | 1.5 | [0.8–2.6] | ||||
| Meta-analysis – 22 studies | 6501 controls |
1 Polymorphism msp1 (mutant homozygotes vs. non-mutant homozygotes).
2 Polymorphism exon 7 (mutant homozygotes vs. non-mutant homozygotes).
3 Polymorphism NAT2*5 (homozygote + heterozygote variants vs. reference homozygotes).
The association between variant CYP1A1 and lung cancer appears to be restricted to non-smokers, and more particularly Caucasian non-smokers (Table 2) in the GSEC pooled studies. The associations with GSTM1 do not appear to be influenced by the smoker status.
Smoking, polymorphisms of CYP1A1 (msp1) and GSTM1 null and lung cancer – Pooled analyses (adjustment for age, gender and study)
| CYP1A1 | GSTM1 (null vs. present) | NAT2 3 | ||||||||||||
| Non-smokers | Smokers | Non-smokers | Smokers | Non-smokers | Smokers | |||||||||
| OR | 95% CI | OR | 95% CI | OR | 95% CI | OR | 95% CI | OR | 95% CI | OR | 95% CI | |||
| Lung cancer | ||||||||||||||
| [17] | 2451 cases | Caucasian | 2.1 | [1.0–4.6] | 1.0 | [0.8–1.4] | ||||||||
| 22 pooled studies1 (GSEC) | 3358 controls | Asian | 1.1 | [0.5–2.3] | 1.3 | [0.6–3.1] | ||||||||
| [21] | 555 cases | Caucasian | 1.7 | [1.0–2.8] | 1.0 | [0.8–1.3] | ||||||||
| 21 pooled studies1 (GSEC) | 2209 controls | Asian | 1.0 | [0.5–2.3] | 1.0 | [0.6–1.7] | ||||||||
| [4] | 1950 cases | 2.1 | [1.2–3.1] | ≈1.1 | ||||||||||
| 11 pooled studies2 (GSEC) | 2617 controls | |||||||||||||
| [18] | 3940 cases | 1.1 | [0.8–1.4] | 1.1 | [1.0–1.2] | |||||||||
| 21 pooled studies (GSEC) | 5515 controls | |||||||||||||
| Upper aerodigestive tract cancers | ||||||||||||||
| [15] | 2334 cases | 1.0 | [0.6–1.5] | 0.9 | [0.5–1.5] | 1.6 | [1.1–2.2] | 1.3 | [1.0–1.7] | |||||
| 11 pooled studies (GSEC) | 2766 controls | |||||||||||||
| Bladder cancer | ||||||||||||||
| [17] | 1530 cases | Caucasian | 1.1 | [0.7–1.8] | 1.6 | [1.3–2.1] | ||||||||
| 8 pooled studies (GSEC) | 731 controls | |||||||||||||
| [20] | 1935 cases | 1.2 | [0.9–1.7] | 1.4 | [1.1–1.6] | |||||||||
| 17 pooled studies (GSEC) | 1444 controls | |||||||||||||
| [16] 4 | 1935 cases | 1.0 | [0.9–1.2] | 1.2 | [1.1–1.5] | |||||||||
| 17 pooled studies (GSEC) | 1444 controls |
1 Polymorphism msp1 (homozygote + heterozygote variants vs. reference homozygotes).
2 Polymorphism exon 7 (homozygote + heterozygote variants vs. reference homozygotes).
3 Polymorphism NAT2*5 (homozygote + heterozygote variants vs. reference homozygotes).
4 OR for gene-smoking interaction estimated in the case-only study.
There are certain inconsistencies in the results of the GSEC analyses. Thus, the Le Marchand pooled analyses [4] appear to indicate that the association between CYP1A1 (exon 7) and lung cancer is more marked for women than for men and more marked for squamous-cell carcinoma than for adenocarcinoma. In contrast, Vineis' analysis [5] (msp1), which was stratified on ethnic origin, showed associations that were systematically more marked for men with, curiously, a significantly lower OR (0.3 [0.1–1.0]) for Asian women. The association was of the same order for the two main histological types.
2.1.2 Aromatic amines and NAT2 polymorphisms in bladder cancer
Aromatic amines were particularly widely used in the dye industry before the potent carcinogenicity to the bladder of benzidine, 4-aminobiphenyl, and auramine and magenta manufacturing had been demonstrated. Certain aromatic amines remain present in occupational settings and 4-aminobiphenyl was recently identified in brown tobacco smoke. Briefly, NAT2 acetylates the oxygen derivatives and reduces the formation of DNA adducts. The NAT2 polymorphisms that slow down that metabolism thus increase the risk of adduct formation. The NAT2*5 polymorphism, responsible for a slow acetylator phenotype, is present in about half of Caucasians [3]. The pooled analysis conducted by Vineis [5] on the GSEC data generated an overall OR estimated at 1.4 [1.1–1.8], associated with the slow acetylator genotype in Caucasians. The association appears restricted to smokers (Table 2).
2.1.3 Other examples
Many other polymorphisms of the genes coding for XME have been studied, sometimes extensively, using the candidate gene approach. Thus, the risk of upper aerodigestive tract cancer is strongly associated with alcohol intake, and polymorphisms of the genes coding for ADH and ALDH, which modify alcohol metabolism, may modulate the risk. The pooled analysis conducted by the IARC on seven studies that collected data on alcohol intake did not however demonstrate an influence of polymorphism on one of the ADH, ADH1C*1 [6]. In contrast, in a multicentre Central European study coordinated by the IARC, the expected interactions were observed: the tumours were negatively associated with the variant allele for ADH1B and positively with the variant alleles for ALDH2. The associations were markedly stronger for intermediate and high alcohol intakes [7]. The international consortium, Inhance, will afford the opportunity of replicating those findings.
2.2 Repair genes
Repair genes are broadly divided into four groups on the basis of whether their products ensure DNA single-strand break repair by base excision repair (BER), double-strand break repair by homologous recombination (HR) or end-joining (EJ), repair of insertions, deletions and mismatches by mismatch repair (MMR), or repair of pyrimidine adducts and dimers by nucleotide excision repair (NER). Certain genes involved in DNA repair also directly affect cell-cycle homeostasis. Some ten familial cancers are due to hereditary deficiency in repair genes. Those cancers include hereditary non-polyposis colon cancer, due to constitutional mutation of genes of the MMR type, and ataxia-telangiectasia (malignant blood diseases and breast cancer) and Xeroderma pigmentosum (skin cancer) due to mutations of HR and NER genes, respectively. Xeroderma pigmentosum is a textbook example of gene–environment interaction, since it results from the association of exposure to UV radiation and presence of a variant allele (seven NER genes may be involved). The 100% prevalence of the exposure masks the interaction.
BER, HR, and EJ enzymes are involved in the repair of the lesions induced by ionizing radiation and chemotherapy (e.g., cisplatin) and NER enzymes in the repair of the lesions induced by UV radiation and adducts generated by chemical exposures. The polymorphisms of the genes coding for those enzymes are thus candidates for modulating the risk of cancer associated with both physical and chemical environmental exposures.
2.2.1 Lung cancer, smoking, and repair gene polymorphisms
The most widely studied polymorphisms in the cancers related to chemical exposures are those of genes XP. The recent meta-analyses, pooling 6 to 8 studies, do not rule out a moderate association between lung cancer and the frequent polymorphisms of genes ERCC2/XPD, XPD-751 and XPD-312 [8,9]. Their interaction with smoking could not be estimated. Variant alleles XRCC1 3194Trp and Arg280His may be negatively associated with the risk of lung cancer in heavy smokers, but this has only been reported by a single large-scale multicentre study conducted in Central Europe [10].
2.3 Cell-cycle genes
Malignant cutaneous melanoma provides an indirect example of interaction between the genes involved in regulating the cell cycle and environmental factors, in this case UV radiation. Certain mutations of genes CDKN2A and CDK4 predispose toward the risk of malignant cutaneous melanoma [11] with high penetrance. However, based on the data generated by a consortium pooling Australian, European, and North-American data, the penetrance of gene CDKN2A varies according to country [12]. The variants of gene MC1R, involved in skin pigmentation, and a high number of nevi would appear to account for the influence of a history of sunburn on the penetrance of CDKN2A [13].
2.4 Assessment: contribution to the elucidation of carcinogenesis and limitations
The incidence of cancers, their multifactorial nature, and the absence of intermediate phenotypes in most cases justify the fact that the case-control approach is usually preferred, together with familial approaches in the event of familial clusters. Certain cohorts, such as the EPIC international cohort, to which E3N constitutes a major French contribution, are sufficiently large to enable powerful case-control studies to be conducted. A specific interest of cohorts is the fact that the specimens are obtained prior to the disease. This sometimes enables use of biological exposure markers and study of the DNA adducts that form during the very early and reversible stages of carcinogenesis. The data on gene–environment interactions in those contexts remain disparate. TDT studies using index case-father-mother triads, which are possible at least for childhood and young adulthood cancers, are increasing. While such studies do not enable direct study of gene–environment interactions, they are complementary to the case-control and case-only approaches, and have the advantage of overcoming potential population sampling bias with respect to ethnic origin (stratification bias) in the study of the association between polymorphism and disease.
The considerable data compilation work implemented by GSEC has enabled large populations for the study of weak associations and an approach to cancer subgroups and rare exposures. This work constitutes a first stage that is ongoing today in the context of numerous consortiums and large-scale multicentre studies.
Population heterogeneity with respect to the risk of cancer associated with environmental exposures clearly exists. However, the influence of a given variant, considered in isolation, does not appear major and few studies have addressed several variants concomitantly. Indubitably, the identification of subpopulations that are more sensitive to certain carcinogens necessitates taking into account a set of polymorphisms and their joint role, but study of the interaction between genes is still at an early stage [14]. The low relative risks associated with variants liable to modulate the exposure-cancer relationship are only detectable in large-scale samples that, in the majority of cases, were obtained by pooling studies designed separately and conducted in different populations. Table 3 shows an example of the heterogeneity of the studies pooled by GSEC to study the interactions between genes and smoking in upper aerodigestive tract cancers [15]. In that example, the associations between upper aerodigestive tract cancers and polymorphisms of CYP1A1 and GSTM1 were greatly influenced by the study designs. The biases of the individual studies are not resolved when the studies are pooled and the value of such studies in terms of the gain in power is relative. Sampling needs to be designed to prevent both bias due to differential stratification on ethnic origin and selection bias on environmental exposures. This rigor has sometimes become secondary in studies of genetic polymorphisms. The Spanish case-control study of bladder cancer [16] is exemplary from this point of view: first because of its large size, which confers strong power, but above all, because all the stages of sampling and exposure evaluation were very carefully implemented, thus minimizing not only bias, but also losses of power.
XME polymorphism and upper aerodigestive tract cancer – Meta-analysis (after [15])
| CYP1A1 | GSTM1 | |||||
| All cancers | 11 | 1.3 | [1.0–1.3] | 26 | 1.2 | [1.1–1.4] |
| Cancer site | ||||||
| Oral | 3 | 1.5 | [0.8–2.8] | 10 | 1.5 | [1.1–2.0] |
| Larynx | 8 | 1.0 | [0.7–1.6] | 9 | 1.1 | [0.9–1.4] |
| Study size | ||||||
| <100 cases or <100 controls | 3 | 1.7 | [0.6–5.3] | 9 | 1.4 | [1.2–1.7] |
| ⩾100 cases and ⩾100 controls | 8 | 1.2 | [0.9–1.6] | 17 | 1.2 | [1.0–1.4] |
| Controls | ||||||
| Healthy hospitalized or population | 7 | 1.4 | [1.0–2.1] | 16 | 1.3 | [1.0–1.6] |
| Hospitalized patients | 4 | 1.1 | [0.9–1.6] | 10 | 1.2 | [1.0–1.3] |
| Matching | ||||||
| Individual | 5 | 1.8 | [1.0–3.5] | 7 | 1.4 | [0.9–2.1] |
| Stratification | 5 | 1.1 | [0.9–1.3] | |||
| None | 6 | 1.1 | [0.8–1.5] | 14 | 1.2 | [1.0–1.4] |
Smoking is such an important risk factor that its association with certain cancers remains detectable, although poorly estimated, in the presence of numerous confounding factors and selection biases. However, this is a particular case and the study of gene–environment interactions requires a special effort to evaluate environmental exposures, particularly since the information on which evaluation is based is frequently retrospective and the lag times are long. However, gene–environment interaction studies are expected to contribute to improving the detection of low relative risks, which requires the most reliable estimates of the exposures. To the author's knowledge, no new environmental risk factor for cancer has been detected by taking into account a susceptibility genotype to date.
3 The debated candidate-gene approach
The number of genes that may reasonably be considered candidates on the dual basis of their probable functional involvement in the carcinogenetic process and of the sufficient allelic frequency of their polymorphisms in the population has considerably increased over the last 10 years. Several hundred genes coding for XME, DNA repair enzymes, cell-cycle enzymes and immune response have become candidates. Depending on the case, other polymorphisms have also become candidates. In parallel, the advent of whole-genome arrays has also led to a review of the candidate-gene strategy and adoption of a screening strategy when the quantities of DNA available enable that approach. The cost remains extremely high, but is not proportional to the number of polymorphisms studied. Thus, the cost differential between covering the main genes of interest and covering the whole genome is tending to become smaller. However, the question of managing the information generated is becoming increasingly complex. The proposed approaches involve stages using exploratory samples, followed by more refined stages during which one attempts to incorporate the information available on haplotypes and the functional pathways between genes in the model.
The high number of candidate polymorphisms per function effectively softens the opposition between the approach consisting in the ‘generation-by-screening’ hypothesis and the one assuming the ‘testing-for-a-given-gene’ hypothesis. Conventionally, the first method is considered unproductive fishing expedition, while the second one is considered intelligent and productive. The candidate genes, and there are already many of them, are probably only a fraction of the genes that may be considered candidates in a few months' or years' time. Even if we restrict our interest to the candidate genes, we cannot escape the issue of multiple testing. If this approach or the whole-genome approach is adopted, the development of methods enabling the extraction of information from the noise in the data derived from high-throughput genotyping systems constitutes a major challenge.
4 Conclusion
Cancers result from complex processes in which genes and environmental factors intervene with multiple interactions between genetic polymorphisms, between environmental factors, and between genetic polymorphisms and environmental factors. The finding is now given information and we cannot escape the resulting complexity, but, with time, our ability to elucidate that complexity will improve. The instruments are being set up: our studies are now equipped with carefully sampled biological collections, high-throughput genotyping systems are becoming available, work on statistical methodologies is ongoing, bioinformatics databases are growing larger and access to them is becoming simpler; international consortiums are being organized. The roles of environmental and genetic factors are being jointly elucidated. The basic rules of epidemiology, which are demanding with respect to sampling, with respect to the histological and molecular criteria for cancer classification, with respect to the evaluation of environmental exposures, their timeframes, quantification and covariables, with respect to study size, and with respect to the rigor of multivariate analyses, are more pertinent than ever before.