

 CC-BY 4.0
CC-BY 4.0
1. Introduction: la modélisation du climat et ses futurs possibles
La science du système Terre est devenue un domaine qui a connu une grande croissance provoquée par les soucis contemporains ayant trait au changement climatique. Prenant la température moyenne globale sur la surface de la planète comme mesure de l’état climatique, on peut poser la question suivante, à quel point vivons-nous dans une époque particulière dans l’histoire géologique de la planète, et si ses variations récentes ont un précèdent dans l’histoire géologique de notre planète. Pour cela, commençons par examiner les variations de température au cours des 500 derniers millions d’années, Figure 1.
Histoire de la température de la planète. Source: Wikipédia.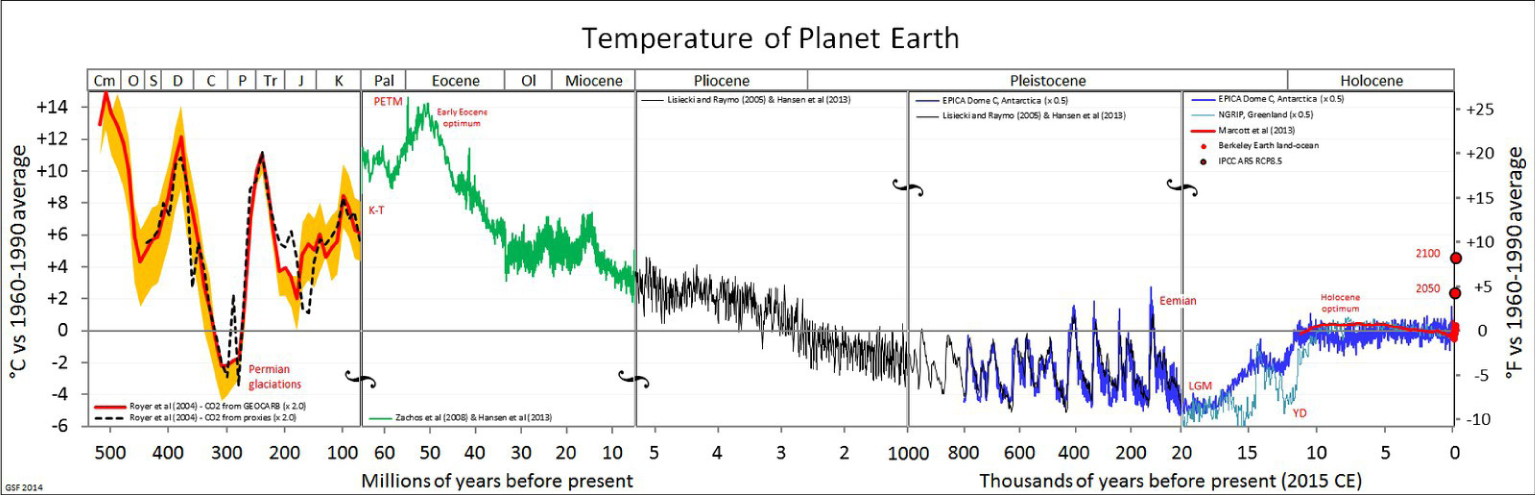
Cette reconstruction de la température globale repose sur l’interprétation de nombreux proxies qui sortent du champ de cet article (Voir la discussion de cette figure dans le célèbre blog RealClimate,1 par exemple).
Les principaux événements présentés ici ne sont pas contestés: par exemple, le maximum thermique du Paléocène-Éocène (PETM) d’il y a environ 50 millions d’années; les grandes oscillations de température menant aux âges de glace, qui ont debuté il y a environ 1 million d’années, et la récente période de stabilité relative commençant il y a environ 10000 ans. Nous voyons, bien sûr, le bond important des températures tout à la fin du registre, représentant la période de très forte influence humaine sur la planète, à partir de la révolution industrielle. Cette augmentation de température peut nous sortir de la zone de confort de température que l’humanité a connu depuis sa sédentarisation [Xu et al. 2020], ce qui représente toute l’histoire de la vie humaine sédentaire: la scène, avec l’agriculture, les villes, et la civilisation. H. Sapiens précède cette « niche » humaine, certes, mais avant cette période, il était nomade, suivant le bord de la glace qui enveloppait périodiquement les masses terrestres. De nombreux événements dans l’histoire des migrations humaines coïncident avec d’importants changements climatiques, e.g. la rencontre entre Néandertaliens et humains modernes [Timmermann 2020]. Ce n’est pas non plus la première fois que nous voyons des événements historiques qui ont un effet sur le climat mondial: l’arrivée des Européens dans le Nouveau Monde a conduit à une « grande mort » des autochtones qui a également laissé des traces sur le bilan carbone et la température [Koch et al. 2019].
Concentrons-nous maintenant sur l’augmentation récente de la température (Figure 1). Les grands débats autour de la politique du changement climatique tournent aujourd’hui autour des causes et des conséquences de ce changement de température, et de ce qu’il signifie pour la vie sur la planète. On sousestime peut-être dans quelle mesure ces résultats dépendent des simulations de la planète entière: la dynamique de l’atmosphère et de l’océan, et leurs interactions avec la biosphère marine et terrestre. Nous montrons ici par exemple la figure SPM.7 du dernier rapport du Groupe d’experts intergouvernemental sur l’évolution du climat (GIEC), paru en 2013 [Stocker et al. 2013] (le prochain rapport, AR6, est en cours de rédaction). Sur cette figure, reproduite ici (Figure 2), nous voyons la capacité des modèles à reproduire le climat du 20ème siècle. Pour le si 21ème siècle, on présente deux « scénarios »: l’un, nommé RCP8.5, représentant un monde sans grand effort pour freiner les émissions de CO2, l’autre, RCP2.6 qui montre la trajectoire thermique d’un monde soumis aux politiques d’atténuation du changement climatique.
La figure SPM.7 du GIEC AR5 [Stocker et al. 2013].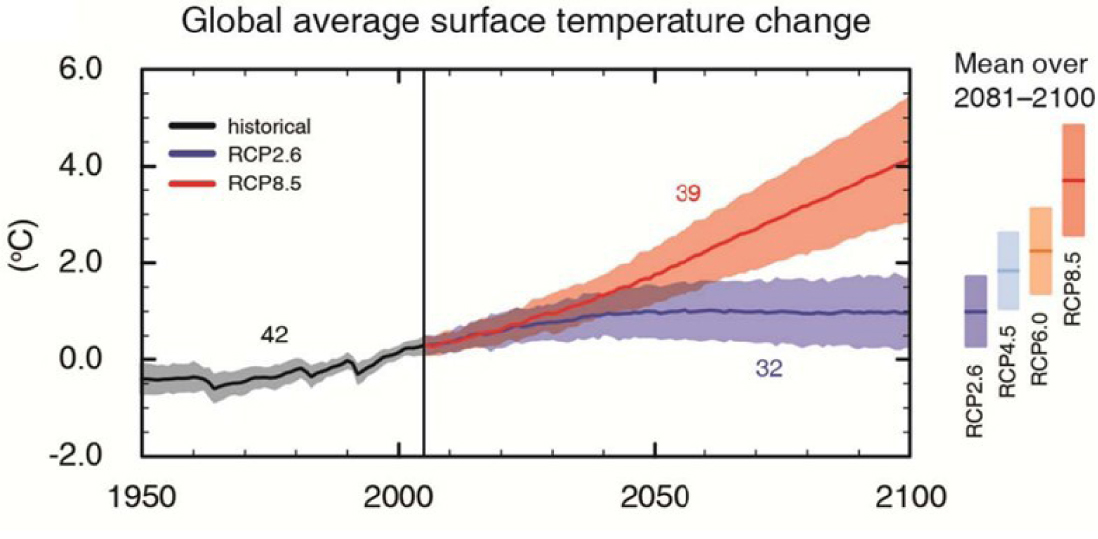
On ne remarque peut-être pas assez à quel point ces chiffres sont dûs aux modèles et aux simulations. Comme nous allons le voir, nous avons passé de nombreuses décennies à construire des modèles, qui sont principalement basés sur des lois physiques bien connues, mais dont de nombreux aspects sont encore imparfaitement maîtrisés. Les bandes colorées autour des courbes représentent une connaissance imparfaite ou une « incertitude épistémique ». Nous estimons les limites de cette incertitude en demandant à différents groupes scientifiques de construire différents modèles indépendants (le nombre à côté des courbes dans la Figure 2 représente le nombre de modèles participant à cet exercice). Les dynamiques sous-jacentes sont « chaotiques », ce qui représente une autre forme d’incertitude.
Le rôle des différents types d’incertitude, tant internes qu’externes, a souvent été analysé (voir l’exemple de la Figure 4 de [Hawkins and Sutton 2009], souvent citée). Il est étudié en exécutant des simulations qui échantillonnent toutes les formes d’incertitude. De tels ensembles de simulations sont également utilisés pour des études sur la détection du changement climatique dans un système à variabilité stochastique naturelle et son attribution à l’influence naturelle ou humaine, par exemple pour se demander si un certain événement tel qu’une canicule (par exemple, [Kew et al. 2019]), est attribuable au changement climatique. Pour de telles études, nous dépendons des modèles pour nous fournir des « contrefactuels » (des états possibles du système qui n’ont jamais eu lieu), où nous simulons des planètes Terre fictives sans influence humaine sur le climat, ce qui ne peut pas être observé.
Le rôle central de la simulation numérique dans la compréhension du système terrestre remonte à l’aube de l’informatique moderne, comme nous le décrirons ci-dessous. Ces modèles reposent sur une base solide de la théorie physique ; c’est pourquoi, nous gardons confiance en eux lors de la simulation de contrefactuels qui ne peuvent pas être vérifiés par des observations. En parallèle, de nombreux projets visent à construire des machines qui apprennent, le domaine de l’intelligence artificielle. Ces deux grandes tendances de l’informatique moderne ont commencé par des débats clés entre des pionniers tels que John von Neumann et Norbert Wiener. Nous montrerons comment ces débats se sont déroulés à l’époque où se développait la simulation numérique de la méteo et du climat. Celles-ci sont réexaminées aujourd’hui, alors que nous avons les mêmes débats aujourd’hui, confrontant la science des données à la science physique, la détection des formes et motifs (« pattern recognition ») dans les données par rapport à la découverte de lois physiques sous-jacentes. Nous montrerons ci-dessous comment les nouvelles technologies liées aux données peuvent conduire à une nouvelle synthèse de la physique et de la science des données.
2. Une brève histoire du temps: les origines de la science météorologique
L’histoire de la prévision numérique de la météo et du climat coïncide presque exactement avec l’histoire de l’informatique numérique elle-même [Balaji 2013]. Cette histoire a été racontée de façon vivante par les historiens [Dahan-Dalmedico 2001; Edwards 2010; Nebeker 1995], ainsi que par les participants eux-mêmes [Platzman 1979; Smagorinsky 1983], qui ont tra vaillé aux côtés de John von Neumann à partir de la fin des années 40. Le développement de la météorologie dynamique en tant que science au 20ème siècle a été raconté par les praticiens (par exemple, [Held 2019; Lorenz 1967]), et nous n’oserions pas essayer de mieux le faire ici. Nous reviendrons sur cette histoire ci-dessous, car certains des premiers débats sont repris aujourd’hui et sont l’objet de cette enquête. Au cours des sept dernières décennies, les méthodes numériques sont devenues le cœur de la météorologie et de l’océanographie. Pour les prévisions météorologiques, une « révolution tranquille » [Bauer et al. 2015] nous a donné des décennies d’avancées continues provenant de modèles numériques intégrant les équations du mouvement pour prédire l’évolution future de l’atmosphère, en tenant compte des effets thermodynamiques et radiatifs et des conditions aux limites évolutives, telles que l’océan et la surface terrestre.
Les études précurseures de Vilhelm Bjerknes (par exemple, [Bjerknes 1921]) sont souvent utiliséss comme marqueur signalant le début de la météorologie dynamique, et nous choisissons d’utiliser Vilhelm Bjerknes pour mettre en évidence une dialectique fondamentale qui a animé le débat depuis le début, et jusqu’à ce jour, comme nous le verrons plus loin. Bjerknes a été le premier à utiliser des équations aux dérivées partielles (la première utilisation des « équations primitives ») pour représenter l’état de la circulation et son évolution temporelle, mais les solutions analytiques étaient difficiles à trouver. Les méthodes numériques étaient également immatures, notamment en ce qui concerne l’étude de leur stabilité comme l’on voit dans les tentatives infructueuses de Richardson [1922] impliquant des milliers de personnes faisant des calculs sur papier. Abandonnant enfin l’approche par équations (l’indisponibilité des données globales clés pendant la guerre y a joué un rôle aussi), Bjerknes s’est reconcentré sur la production des cartes des masses d’air et de leurs fronts [Bjerknes 1921]. Les prévisions étaient souvent basées sur une vaste bibliothèque de cartes papier pour trouver une carte qui ressemblait au présent, et à la recherche de la séquence suivante, ce que nous reconnaîtrions aujourd’hui comme la méthode analogue de Lorenz [1969]. Nebeker a commenté l’ironie que Bjerknes, qui a posé les fondements de la météorologie théorique, a également été celui qui a développé la prévision pratique avec des outils « qui n’étaient ni algorithmiques ni basés sur les lois de la physique » [Nebeker 1995].
On voit ici, en la seule personne de Bjerknes, plusieurs voix dans une conversation qui continue à ce jour. D’un côté on conçoit la météorologie comme une science, où tout peut être dérivé des équations de la mécanique des fluides classique. Une seconde approche est orientée spécifiquement vers l’objectif de prédire l’évolution future du système (prévisions météorologiques) et le succès est mesuré par la compétence prévisionnelle, par tout moyen nécessaire. Cela pourrait, par exemple, être en créant approximativement des analogues à l’état actuel de la circulation et en s’appuyant sur des trajectoires passées similaires pour deviner la météo future. On peut avoir une compréhension du système sans la compétence de le prédire; on peut avoir des prédictions habiles innocentes de toute compréhension. On peut avoir une bibliothèque des données d’apprentissage, et apprendre la trajectoire du système à partir de cela, au moins dans une certaine approximation ou sens probabiliste. Si aucun analogue n’existe dans les données d’entraînement, aucune prédiction n’est possible. Ce que l’on a appelé plus tard des prévisions « subjectives » dépendaient beaucoup de l’expérience et du souvenir du météorologue, qui n’était généralement pas bien versé en météorologie théorique, comme le remarque Phillips [1990]. Des évènements à évolution rapide en l’absence des précurseurs évidents dans les données étaient souvent absents dans les prévisions.
L’introduction par Charney d’une solution numérique à l’équation de la vorticité barotrope, et son exécution sur ENIAC, le premier ordinateur numérique opérationnel [Charney et al. 1950], a essentiellement conduit à un renversement complet de fortune dans la course entre la physique et la reconnaissance des formes. Les calculateurs programmables (où les instructions de calcul étaient chargées en même temps que des données) ont été la prochaine avancée, et le calcul de point de repère de Phillips [1956] est venu peu après.
Il n’a pas fallu longtemps pour que les prévisions basées sur des modèles numériques simplifiés surpassent les prévisions subjectives. La compétence de prévision, mesurée (comme aujourd’hui!) par des erreurs dans la hauteur géopotentielle de 500 hPa, était nettement meilleure dans les prévisions numériques après la percée de Phillips (voir la Figure 1 dans [Shuman 1989]). Il est maintenant considéré comme un fait parfaitement établi que les prévisions sont basées sur la physique: Edwards [2010] remarque qu’il a eu du mal à convaincre certains des scientifiques qu’il a rencontrés dans les années 90, que des décennies se sont écoulées depuis la fondation de la météorologie théorique avant que la physique heuristique simple et la reconnaissance de modèle sans théorie ne deviennent obsolètes dans les compétences en prévision.
En utilisant les mêmes méthodes exécutées pendant de très longues périodes (ce que von Neumann a appelé des « Prévisions infinies » [Smagorinsky 1983]), le domaine de la simulation climatique s’est développé au cours des mêmes décennies. Tandis que de simples arguments radiatifs pour le réchauffement induit par le CO2 ont été avancés dès le XIXe siècle, la simulation numérique a permis de caractériser en détail la réponse dynamique de la circulation générale à une augmentation du CO2 atmosphérique (par exemple, [Manabe and Wetherald 1975]). Des modèles de circulation océanique avaient commencé à apparaître (par exemple [Munk 1950]) et démontraient des variations basse fréquence (selon les normes météorologiques atmosphériques) et l’importance du couplage océanique [Namias 1959]. Le premier modèle couplé de Manabe and Bryan [1969] est apparu peu après. La météorologie numérique a aussi conduit par hasard à l’une des découvertes les plus profondes de la seconde moitié du 20e siècle, à savoir que même les systèmes complètement déterministes ont des limites à la prévisibilité de l’évolution future du système, le célèbre « attracteur étrange », marque de « chaos » [Lorenz 1963]. Le simple fait de connaître la physique sous-jacente ne conduit pas à une compétence à prédire au-delà d’une limite temporelle. Bien avant Lorenz, Norbert Wiener avait declaré que ce serait une « mauvaise technique » [Wiener 1956] d’appliquer des équations différentielles lisses à un monde non linéaire où les erreurs sont grandes et la précision des observations est faible. Lorenz l’a démontré dans un système déterministe mais imprévisible de seulement trois variables, dans l’un des résultats récents les plus beaux et les plus profonds de la physique.
Pourtant, les statistiques des fluctuations météorologiques de la limite asymptotique pourraient encore être étudiés [Smagorinsky 1983]. En une décennie, ces modèles qui étaient les outils de base du métier pour étudier la réponse d’équilibre asymptotique du système terrestre aux changements du forçage externe, sont devenus le nouveau champ des sciences climatiques computationnelles.
Les résultats pratiques de ces études sont la réponse du climat aux phénomènes anthropiques. Les émissions de CO2 ont alarmé le public avec la publication du rapport Charney en 1979 [Charney et al. 1979]. La science climatique computationnelle, avec maintenant des ramifications sociétales à l’échelle planétaire, est devenue un domaine en pleine expansion qui s’étend sur de nombreux pays et laboratoires, qui pouvaient désormais tous aspirer à l’échelle de calcul nécessaire pour étudier les implications du changement climatique anthropogène. Il n’y avait jamais assez d’informatique: il était clair, par exemple, que la représentation des nuages était une inconnue majeure dans le système (comme indiqué dans le Rapport Charney) et était (et est toujours, voir [Schneider et al. 2017]) bien en dessous de la résolution spatiale des modèles capables d’exploiter les plus puissants ordinateurs disponibles. Les modèles étaient avides de ressources, prêts à consommer tout ce qui leur est fourni pour le calcul. Une compréhension plus sophistiquée du système terrestre a également commencé à ajouter des processus dans les simulations, constituant maintenant un ensemble intégré avec la physique, la chimie et la biologie. Le coût de calcul (sans parler de l’énergie et l’empreinte carbone) de ces simulations devient non négligeable [Balaji et al. 2017]. Pourtant, des erreurs récalcitrantes subsistent. Le biais dit « double ITCZ », par exemple, n’a pas été éliminé malgré de nombreuses reformulations et réglages sur plusieurs générations de modèles du climat [Li and Xie 2014; Lin 2007; Tian and Dong 2020]. Il est soutenu par beaucoup qu’aucun tripotage avec les paramétrisations ne peut corriger certains de ces biais « récalcitrants », et que seule la simulation directe est susceptible de conduire à des progrès (par exemple [Palmer and Stevens 2019], Encadré 2).
La révolution commencée par von Neumann et Charney à l’IAS, et les décennies suivantes de croissance exponentielle en informatique, ont conduit à d’énormes progrès ainsi qu’à des indicateurs de progrès encore ambigus. Ce qui ressemblait initialement à un triomphe clair de la physique, allié aux avancées informatiques et algorithmiques, montre désormais des signes de décrochage, l’accumulation de « détails » dans les modèles — à la fois dans la résolution et la complexité — entraîne certaines difficultés dans l’interprétation et la maîtrise du comportement des modèles. Cela conduit à un tournant dans la science informatique du climat qui peut n’être pas moins ambitieux que celui de Princeton en 1950.
Juste au moment où l’état des lieux de l’informatique climatique a été examiné [Balaji 2015], les contours de la renaissance des réseaux de neurones artificiels (RNA) et de l’apprentissage automatique (ML) commençaient à prendre forme. Comme indiqué dans la Section 2, les RNA existaient aux côtés des modèles de von Neumann et Charney pendant des décennies, mais peuvent avoir « langui » car la puissance de calcul et le parallélisme n’étaient pas disponibles. Les nouveaux processeurs émergeant aujourd’hui sont parfaitement adaptés au ML: le calcul typique d’apprentissage en réseaux profonds (« deep learning » ou DL) se compose d’une algèbre linéaire dense, parallélisable presque à volonté, capable de réduire la bande passante mémoire à précision réduite sans perte de performances. Des processeurs tels que les TPU (l’unité à traitement tensoriel) se sont montrés capables d’exécuter une charge de travail DL typique proche de la performances maximales de la puce [Jouppi et al. 2017].
Alors que les promesses des réseaux de neurones ne s’étaient pas concrétisées après leur découverte dans les années 1960 (par exemple, le modèle « perceptron » de [Block et al. 1962]), ces méthodes ont connu une résurgence remarquable dans de nombreux domaines scientifiques ces dernières années, tandis que les approches classiques stagnent. Alors que la communauté météorologique avait initialement quelque réticences pour ces outils (pour les raisons décrites dans [Hsieh and Tang 1998]), les deux ou trois dernières années ont vu une grande efflorescence de la littérature appliquant l’apprentissage automatique (« machine learning », ou ML) — comme on dit maintenant — dans la science du système terrestre. Nous soutenons dans cet article que cela représente un changement radical dans la science informatique du système terrestre qui rivalise avec la révolution de von Neumann. En effet, certains des débats actuels autour de l’apprentissage automatique — opposant les méthodes « sans modèle » à « l’IA interprétable »2 par exemple — ressemblent à ceux qui ont eu lieu dans les années 1940–1950.
3. Apprendre la physique à partir des données
Rappelez-vous que V. Bjerknes s’est éloigné de la météorologie théorique en constatant que les outils à sa disposition n’étaient pas suffisants pour faire des prédictions à partir de la théorie. Il est possible que l’état du calcul actuel constitue un parallèle historique, et nous nous tournerons peut-être également vers des prédictions pratiques, sans théorie. Un exemple est la prévision des précipitations à partir d’une séquence d’images radar [Agrawal et al. 2019] (essentiellement, extrapoler diverses transformations optiques telles que la translation, rotation, étirement, intensification), qui se montre compétitive vis à vis des prévisions à court terme basées sur des modèles. Les méthodes ML ont montré une compétence de prévision exceptionnelle sur de plus longues échelles de temps, y compris la percée de la « barrière du printemps » (c’est le nom donné à un réduction des compétences prévisionnelles dans les modèles initialisés avant le printemps boréal) dans la prévisibilité du phénomène ENSO [Ham et al. 2019]. Fait intéressant, la méthode analogue de Lorenz [1969] montre également une compétence de prévoir ENSO à plus long terme (sans barrière du printemps) par rapport aux modèles dynamiques [Ding et al. 2019], un retour aux premiers jours de la prévision décrit dans la Section 2. Ces succès et d’autres dans le domaine purement « axé sur les données » (bien que les articles sur l’ENSO cités ici utilisent les sorties du modèle comme données d’apprentissage) ; les prévisions ont conduit à la spéculation dans les média que le ML pourrait en effet rendre obsolètes les prévisions basées sur la physique (voir par exemple « Could Machine Learning Replace the Entire Weather Forecast System? »3 in HPCWire). Des méthodes ML (dans ce cas, réseaux de neurones récurrents) se sont également montrées capables de reproduire une série chronologique à partir de systèmes chaotiques canoniques avec une prévisibilité qui va au-delà de ce que la théorie des systèmes dynamiques suggère [Pathak et al. 2018] laquelle prétend en effet être « sans modèle », ou [Chattopadhyay et al. 2020]). Est-ce à dire que nous sommes revenus en arrière sur la révolution de von Neumann, avec un retour aux prévisions à partir de la reconnaissance des formes plutôt que la physique? La réponse dépend bien sûr de l’hypothèse que les exemples donnés au système procurent un échantillonnage complet de tous les états possibles du système. Pour le système Terre, ceci est une proposition douteuse, car il existe une variabilité à toutes les échelles de temps, y compris celles qui dépassent la période pour laquelle nous avons des observations fiables, l’ère des satellites par exemple. Un problème clé pour toutes les approches basées sur les données est celui de la généralisabilité au-delà des limites des données d’apprentissage.
Passons au climat, nous examinerons les aspects des modèles du système terrestre qui bien que largement basés sur la théorie, sont structurés autour d’une formulation empirique des principes. Ces domaines sont évidemment mûrs pour une approche plus directement basée sur les données. Ces modèles sont souvent basés sur les composants paramétrés du modèle qui traitent de la « sous-grille » physique inférieure à la troncature imposée par la discrétisation. Une caractéristique clé de l’écoulement des fluides géophysiques est la cascade de turbulence tridimensionnelle continue de l’échelle planétaire jusqu’à l’échelle de longueur de Kolmogorov (voir par exemple [Nastrom and Gage 1985], Figure 1), qui doit être tronquée quelque part pour une représentation numérique. La représentation de la turbulence sous réseau basée, sur le ML est actuellement un domaine actif [Duraisamy et al. 2019]. D’autres aspects de sous-grille spécifiques à la modélisation du système Terre existent, où le ML pourraient jouer un rôle, notamment en ce qui concerne le transfert radiatif et la représentation des nuages.
Les RNA ont l’avantage immédiat d’être souvent beaucoup plus rapides que le composant qu’ils remplacent [Krasnopolsky et al. 2005; Rasp et al. 2018]. De plus, les procédures d’étalonnage de sont très inefficaces avec les modèles complets et peuvent être considérablement accélérées en utilisant des émulateurs dérivés de l’apprentissage [Williamson et al. 2013].
Le ML pose néanmoins un certain nombre de questions difficiles que nous sommes maintenant activement an train de traiter. Les problèmes habituels de savoir si les données sont représentatives et complètes, et sur la généralisabilité de l’apprentissage, continuent de se poser. Il y a une énigme à résoudre pour décider où se trouve la frontière entre le fait d’être axé sur les connaissances physiques et sur les données. Nous décrivons certaines des questions clé abordées dans la littérature actuelle. Nous prendrons comme point de départ, une composante particulière du modèle (comme la convection atmosphérique ou la turbulence dans les océans) qui est maintenant augmentée par l’apprentissage. Prenons la structure du système sous-jacent tel qu’il est maintenant, et utilisons l’apprentissage comme méthode de réduire l’incertitude paramétrique? Les méthodes émergentes nous permettent potentiellement de traiter les erreurs paramétriques et les erreurs structurelles sur une base commune (par exemple [Williamson et al. 2015]), mais nous pouvons toujours choisir d’être sans structure, ou tenter de découvrir la structure elle-même [Zanna and Bolton 2020].
Si nous nous débarrassons de la structure sous-jacente des équations, nous avons un certain nombre de problèmes à résoudre. Comme l’apprentissage est au mieux aussi bon que les données d’apprentissage, nous pouvons constater que le RNA résultant viole certaines lois de base (telles que les lois de conservation) ou ne se généralise pas bien [Bolton and Zanna 2019]. Cela peut être abordé par un choix approprié de fonctions propres sur lesquelles effectuer l’apprentissage, voir Zanna and Bolton [2020]. Une considération similaire a été observée [O’Gorman and Dwyer 2018], où un modèle entraîné en utilisant le climat actuel, se montre incapable de se généraliser à un climat plus chaud, mais la perte de généralisation pourrait être traitée par un choix de la variable physique de base. Idéalement, nous aimerions aller beaucoup plus loin et apprendre réellement la physique sous-jacente.
Il y a eu des tentatives pour identifier les équations sous-jacentes pour des systèmes bien connus [Brunton et al. 2016; Schmidt and Lipson 2009] et les efforts en cours dans le domaine de la modélisation du climat également, pour trouver des paramétrisations à partir des données. Enfin, nous posons le problème du couplage. Nous avons noté précédemment le problème de l’étalonnage des modèles, qui se fait d’abord au niveau des composants, pour amener chaque processus individuel dans les contraintes d’observation, puis dans une deuxième étape de calibration par rapport à l’ensemble du contraintes globales, telles que l’équilibre radiatif du sommet de l’atmosphère [Hourdin et al. 2017]. La question de la stabilité des RNA lorsqu’ils sont intégrés dans un système couplé est également à l’étude en ce moment (par exemple [Brenowitz et al. 2020]). Il faut savoir choisir d’abord l’unité d’apprentissage: serait-ce un processus individuel, ou le système entier?
4. Récapitulatif
Nous avons mis en évidence dans cet article une progression historique de la modélisation du système Terre, où la révolution de von Neumann nous a permis de passer de la reconnaissance des motifs à la manipulation numérique directe des équations de la physique.
Nous avons décrit comment l’apprentissage automatique statistique de quantités massives de données offre la possibilité de s’inspirer directement d’observations pour prédire le système terrestre, une transition qui est potentiellement aussi vaste que celle de von Neumann.
À première vue, il peut sembler que nous tournons le dos à la révolution de von Neumann, passant de la physique à la simple recherche et au suivi de modèles de données. Bien que ces des approches en « boîte noire » puissent en effet être utilisées pour certaines activités, nous constatons de nombreux efforts pour s’assurer que les algorithmes d’apprentissage respectent bien les contraintes physiques même s’ils n’emergent pas directement des données. La science est bien sûr basée sur des observations. Mais « la théorie est chargée de données, et les données sont chargées de théorie », selon la formule prononcée par le philosophe Pierre Duhem. Edwards [2010] a proposé que la même idée s’applique aux modèles: les modèles sont chargés de données, mais les données sont également chargées de modèles. Nous le voyons clairement en ce qui concerne les données climatiques qui sont souvent basées sur ce qu’on appelle la « réanalyse », un ensemble de données mondiales, créé à partir d’observations clairsemées et extrapolées en utilisant des considérations théoriques. Un résultat récent [Chemke and Polvani 2019], intéressant, montre cette énigme, où il s’avère que les modèles du futur sont corrects mais que les données du passé (à savoir les réanalyses) sont erronées!
Le domaine a également besoin de modèles pour construire des « contrefactuels » par rapport auxquels la réalité actuelle est comparée. Cela signifie que même les algorithmes d’apprentissage doivent utiliser des résultats générés par les modèles en données d’apprentissage, plutôt que des observations. Les résultats de l’apprentissage automatique à partir de ces données simulées apprendront à les émuler, passant ainsi de la simulation à l’émulation.
Le réseau mondial Earth System Grid Federation.
Cela est déjà devenu évident dans les tendances récentes, où nous voyons des données simulées devenir de taille comparable aux quantités massives de données d’observation par satellite [Overpeck et al. 2011]. Nous voyons dans la Figure 3 la nouvelle « vaste machine » de données à travers le monde à partir de simulations distribuées pour le GIEC, pour l’évaluation actuelle suivant celle de la Figure 2. Il est impératif que ces données soient correctement étiquetées et stockées et donc susceptibles d’être étudiées par les outils du machine learning. Cette infrastructure de données mondiale montre les possibilités d’une nouvelle synthèse des connaissances physiques et des mégadonnées: à travers l’émulation de données simulées, nous tenterons d’extraire des connaissances physiques sur l’état de la planète et la compétence de prédire son évolution future.
Financement
V. Balaji est soutenu par le Cooperative Institute for Modeling the Earth System, Princeton Université, sous le prix NA18OAR4320123 de la National Oceanic and Atmospheric Administration, US Department of Commerce, et par l’aide d’État française Make Our Planet Great Again gérée par l’Agence Nationale de Recherche dans le cadre du programme « Investissements d’avenir » avec la référence ANR-17-MPGA-0009.
Les déclarations, constatations, conclusions et recommandations sont celles des auteurs et ne reflètent pas nécessairement les vues de l’Université de Princeton, de la National Oceanic and Atmospheric Administration, du Department of Commerce américain ou de l’ Agence Nationale de Recherche française. Les auteurs déclarent n’avoir aucun intérêt concurrent.
Remerciements
Je remercie Ghislain de Marsily, Fabien Paulot, et Raphael Dussin pour leur lecture soigneuse des versions initiales de cet article ce qui a permis d’améliorer considérablement le manuscrit. Je remercie l’Académie des sciences et les organisateurs du colloque « Face au changement climatique, le champ des possibles » en janvier 2020, de m’avoir accordé l’opportunité d’y participer et de contribuer à ce numéro spécial.
1 http://www.realclimate.org/index.php/archives/2014/03/can-we-make-better-graphs-of-global-temperature-history, récupéré le 31 juillet 2020.
2 L’ IA, ou intelligence artificielle, est un terme que nous éviterons généralement ici au profit de termes comme l’apprentissage automatique, qui mettent l’accent sur l’aspect statistique, sans impliquer une perspicacité.
3 https://www.hpcwire.com/2020/04/27/could-machine-learning-replace-the-entire-weather-fore récupéré le 31 juillet 2020.