

1 Introduction
Neighbouring plants generally compete for the limiting resources and, in order to understand the effect of neighbouring plants, it is essential to compare and test different hypotheses of the effect of neighbours. It is possible to test many simple hypotheses using informal and verbal models, but verbal models may be susceptible to vagueness and logical pitfalls, especially if the model is complicated. On the other hand, by constructing a mathematical model, which encapsulates the hypothesis that we want to test, we are forced to be precise in the description of the functional relationships.
Two fundamentally different approaches can be made when modelling plant growth.
- (1) The expected effects of the abiotic and biotic environment, including effects of neighbouring plants, on plant growth may be modelled using mechanistic plant models. In a mechanistic plant model [1–4], the growth rate of different plant species is modelled as a function of the limiting resource(s). Such mechanistic plant models ideally contain detailed information of how plants respond to different environments, which enables predictions of plant growth as a function of the environment. In reality, the models necessarily contain many more or less alleged functional relationships and many parameters that are difficult or impossible to estimate jointly.
- (2) A less ambitious approach, which will be followed here, is to describe plant growth using empirical models that are fitted to plant growth data. Empirical models are mathematically simple models with relatively few biologically interpretable parameters, and due to their simplicity it is possible to jointly estimate all the parameters in the model from a single dataset. The joint estimation of parameters is important if there is any covariability between parameters. The empirical models rely heavily on data and the model will never be better than the underlying data; thus, it is important to be conscious of the limitations of empirical models, e.g., it is not possible to make predictions outside the domain of the data. Since plant growth data typically has been obtained at a fixed environment, empirical models have been criticised for having limited predictive power; however, this limitation may be circumvented by obtaining ecological data along an environmental gradient. In constructing empirical plant growth models, there is a delicate balance between keeping models simple and describing the biological system in sufficient detail to obtain the desired information, i.e., performing tests of investigated hypotheses or obtaining posterior distributions of biological parameters.
2 Richards growth model
Several sigmoidal or saturated growth models have been proposed to describe growth of individual plants, e.g., Gompertz, and logistic growth models where the main difference between the models is when the plant experiences its maximum growth rate [5]. The maximum growth rate occurs at the point when the sigmoidal growth curve shifts from being convex to being concave (the inflection point) and, in the Richards growth model [6], this inflection point is modelled by a free parameter. The determination of the inflection point by a free parameter makes the Richards growth model relatively flexible and inclusive of the other sigmoidal growth models (Fig. 1). Rather than assuming a fixed point of inflection, the Richards growth model is assumed in the following, since there is no general theory that predicts at what growth stage plants experience their maximum growth rate, and the inflection point has been shown to depend on density [7].
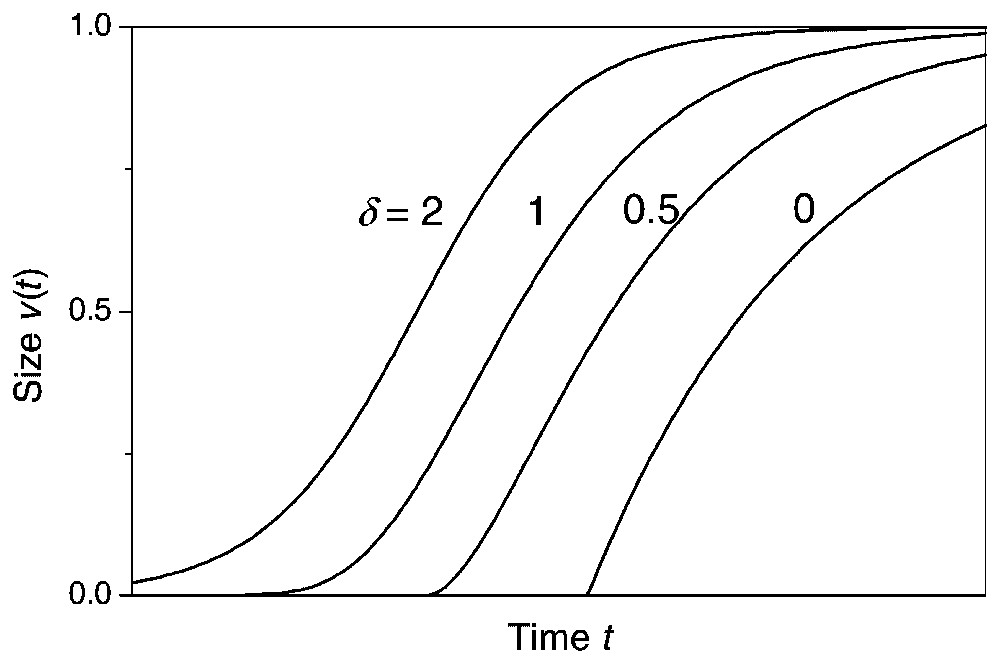
Curves of Richards growth model for various δ, w=1 and κ is 0.75, 0.5, 0.375 and 0.25, respectively. The parameter γ is changed each time so that the curves do not sit on top of one another. The variable inflection point controlled by the parameter δ makes the Richards growth model inclusive of the other sigmoidal growth functions, e.g., the logistic model (δ=2), the Gompertz model (δ=1), and the monomolecular model (δ=0). From [6]. Masquer
Curves of Richards growth model for various δ, w=1 and κ is 0.75, 0.5, 0.375 and 0.25, respectively. The parameter γ is changed each time so that the curves do not sit on top of one ... Lire la suite
Individual plant growth will in the following be measured by the absolute growth rate, which is the increase in some measure of plant size, e.g., biomass, per time. In the Richards growth model the growth of a plant at time t, is assumed to be proportional to the plant size at time t multiplied by a saturating function of the plant size at time t.
| (1) |
The variable inflection point of the Richards growth model includes other sigmoidal growth functions as special cases (Fig. 1) [5], i.e., the monomolecular model (δ=0), the von Bertalanffy model (δ=2/3), the logistic model (δ=2), and by taking the limit as δ→1 the Gompertz model:
| (2) |
| (3) |
3 Size-asymmetric growth
The Richards growth model (1) adequately describes the growth of a single plant or plant growth in a monoculture of identical plants. However, the plants in a monoculture are rarely identical. There may be variation in the time of germination, distance to nearest neighbour, or in the microenvironment that leads to variable plant sizes. If the plant growth is limited by a resource that may be monopolised, e.g., light, then asymmetric competition may occur and the variation among plant sizes may increase with time more than expected under a Richards growth model [7,9–12].
In the Richards growth model, the growth of a plant is assumed to be proportional to the plant size multiplied by a saturating function. In order to allow for size-asymmetric growth, the assumption of proportional growth may be generalised so that the growth of plants is proportional to a power function of their size [7,13–15]:
| (4) |
Classification of the degree of size-asymmetry based on the relationship between size and growth rate. Terminology adapted after [16]
| Parameter value | Definition | |
| Complete symmetry | a=0 | All plants have the same growth rate irrespective of their size |
| Partial size-symmetry | 0<a<1 | The growth rate is less than proportional to the size of the plant |
| Perfect size-symmetry | a=1 | The growth rate is proportional to the size of the plant |
| Partial size-asymmetry | a>1 | The growth rate is more than proportional to the size |
| Complete size-asymmetry | a=∞ | Limiting case where only a few dominating plants are growing; all other plants have stopped growing |
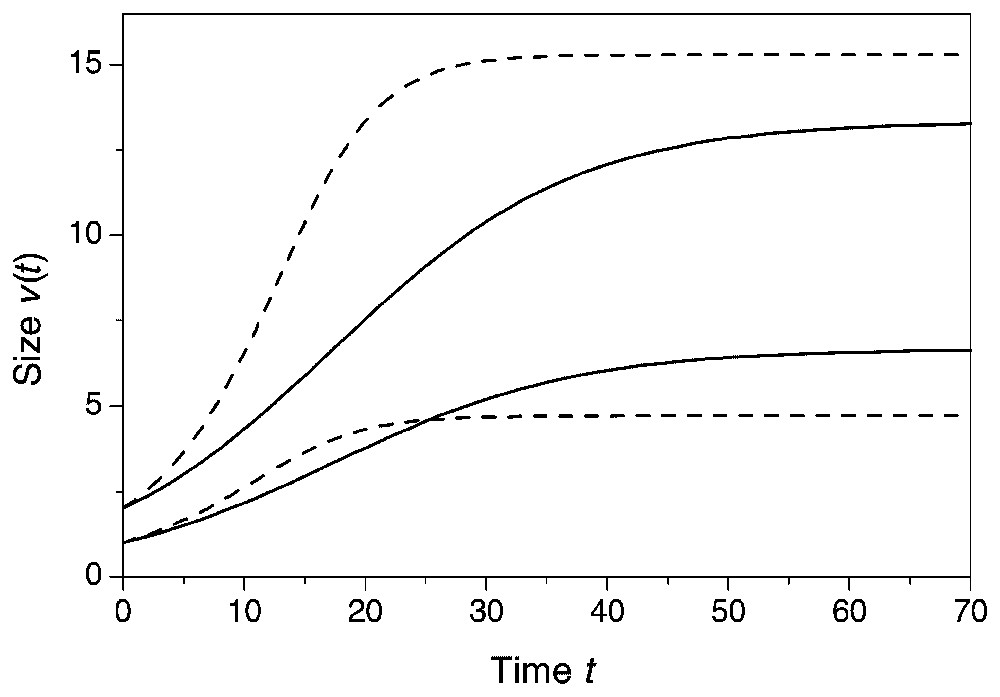
Richards growth model for two interacting plants with and initial size of one and two, respectively at two levels of the degree of size-asymmetry. Full line: a=1, w=10, κ=0.1, δ=2. Dashed line: a=1.5, w=10, κ=0.0667, δ=2. Notice that the size difference increases with a.
In order to take the effect of plant size variation on the growth of individual plants into account, an individual-based Richards growth model may be formulated by generalising (1) and (2) with respect to size-asymmetric growth (4). Assume a monoculture of n competitively interacting plants of variable size, then the growth of plant i at time t may be expressed by n coupled differential equations:
| (5) |
The individual-based Richards growth model cannot be solved in the general case, and in order to fit the growth model to growth data, the model has to be solved numerically for each set of parameter values used in a maximum-likelihood fitting procedure [7].
4 Effect of plant density
In a number of empirical studies (e.g., [17–20]) the class of hyperbolic size-density response functions has been demonstrated to fit plant competition data well at different growth stages and for different measures of plant size. [21] introduced a hyperbolic size-density response function for a single species:
| (6) |
It has been found that it is primarily the ratio θ/φ in the Bleasdale–Nelder model (6) that determines the shape of the plant size-density curve [5,22]. Therefore, a simpler model has been proposed [23,24]:
| (7) |
The individual-based Richards growth model (5) may be extended to include growth at different densities by generalising the four parameters in the individual-based growth model (5) to functions of density. It is apparent that the average final size, w in (5), may be generalised by a plant size-density model, e.g., (7), w(x)=wm/(1+βxφ), and assuming that the initial growth rate is independent of density, (κa)/(δ−1)=c, then κ may be generalised to κ(x)=c(δ(x)−1)/a(x), where c is a constant. The functions δ(x) and a(x) may be expected to be decreasing and increasing functions of density, respectively, and likely candidate functions may be δ(x)=δ0exp(−δ1x) and a(x)=a0+a1x. Generalising the individual-based Richards growth model (5) with respect to density requires at least four new free parameters, thus the fitting and especially the testing of biological hypotheses will require very good plant growth data and has not been done yet.
5 Modelling spatial effects
The plant size-density models (6) and (7) are mean-field models [25,26], where it is assumed implicitly that all individuals at a certain density have the same size, and every plant has the same effect of any other plant. The mean-field approach is a sensible place to begin in the modelling of plant–plant interactions [27], but it ignores much of what is important about the dynamics of plant communities [25]. In reality, interactions typically are restricted to a subset of the individuals as and the likelihood that two plants will interact is most probably a decreasing function of the distance between them [28].
As explained above, the negative interactions between neighbouring plants are caused by competition for the same resources. The ways the limiting resources are distributed among the neighbouring plants depend on the type of resource that is limiting for growth, the interacting plant species and their size. Different theoretical models, which describe the distribution of resources, have been proposed. However, the development of theory in this area has been more rapid than the compilation of relevant ecological data and it is difficult to assess the validity of the different models.
The ‘zone of influence’ model is a resource-uptake-based model, which allows for differences in plant size [29–32]. Each plant is assumed surrounded by an imaginary circle, which symbolises the area from which the plant may extract resources. When the plant grows, the radius of the circle expands according to some species-specific rules. After a while, the imaginary circles of two neighbouring plants may overlap and the resources in the overlapping area are shared among the plants according to species-specific rules of sharing resources. For example, the largest plant may get all the resources in the overlapping area (complete size-asymmetric competition), or plants may share the resources in the overlapping area proportionally to their size (perfect size-symmetric competition). The ‘zone of influence’ model may be generalised by assuming that the influence of the plant within the zone is a decreasing function of the distance from the plant [33].
An empirical spatial model called the neighbourhood model assumes that a plant only competes with the neighbours that are positioned within a fitted fixed radius of the plant [34,35]. The competitive effect of the neighbours and the plant itself (self-shading) on the growth of the plant is described by a mean-field plant size-density model. The neighbourhood model has the advantage that it is readily fitted to data [36]. However, in a comparative test between different spatial models on natural populations of Lasallia pustulata [37], the neighbourhood model (number of plants within a circle with fixed radius) was a worse predictor than the distance to the nearest neighbour, which is also a conceptually simpler model.
Using the distances between plants and a given functional relationship that describes the effect of interplant distances on the competitive interactions, U, such a competitive neighbourhood function may be used to generalise the individual-based Richards growth models (5) with respect to the spatial setting:
| (8) |
| (9) |
The fitting of such a spatial explicit individual-based Richards growth model (8) requires growth data of individual plants with a known spatial position; the growth model will probably be valuable in the analysis of tree growth, where spatially explicit long-term growth data exist (e.g., [40]).
Acknowledgements
Thanks to Jacob Weiner for inspiring discussions and two anonymous reviewers for fruitful suggestions.