

1 Introduction
Ionic liquids (ILs) are salts with a very low melting temperature and typically consist of a large organic cation and an inorganic polyatomic anion [1]. In the last few years, ILs have drawn the attention of the scientific community, and hundreds of studies that involve different aspects of ILs have been published in the scientific literature. From the scientific and industrial points of view, a fundamental understanding of the physico-chemical properties of ILs is needed before their application to several processes. For instance, knowledge of some basic properties can be useful for fluid property estimation, thermodynamic property calculations, and phase equilibrium [2].
Regarding ILs, thermal conductivity is important to be known before obtaining the heat transfer coefficient of fluids that is essential for the design of heat transfer fluid and equipment [3]. There is a large variety of analytical expressions that allow the correlation and prediction of thermal conductivity. In the case of ILs, these expressions are usually based on the use of adjustable parameters of each fluid (correlations) [3–6], or based on the group contribution methods (GCMs). In this context, Gardas and Countinho [7], and Albert and Müller [8] proposed a GCM for predicting the thermal conductivity of imidazolium, pyrrolidinium, and phosphonium ILs with a deviation below the mean. Wu et al. [9] proposed another GCM for predicting the thermal conductivities of ILs, in combination with the Valderrama's group contribution method for critical properties of ILs [10]. However, to the best of the author's knowledge there is no application of GCM for the estimation of the thermal conductivity of ILs as a function of temperature and pressure, as presented here, and certainly there is not any publications on the estimation of thermal conductivity for a heterogeneous set of ILs using a hybrid artificial neural network.
The relationship between the physical and thermodynamic properties is highly nonlinear, and consequently an artificial neural network (ANN) can be a suitable alternative to modelling underlying thermodynamic properties. An ANN is an especially efficient algorithm for approximating any function with a finite number of discontinuities by learning the relationships between the input and output vectors [11]. Therefore, an ANN is an appropriate technique for modelling the nonlinear behaviour of thermophysical properties [2]. In this context, Hezave et al. [12] presented a neural network model for predicting the thermal conductivity of ionic liquids using temperature T, pressure P, molecular weight MW, and melting point temperature Tm of ILs as input parameters.
In this work, thermal conductivities of several ILs at different temperatures and pressures were correlated and estimated using an ANN optimized with a genetic algorithm (GA) [13] in order to update the weights of the network.
2 Neural network and genetic algorithm (ANN+GA)
The most successful and frequently used type of neural network, a multilayer feed-forward neural network with a back-propagation learning algorithm (gradient descent error), was implemented in the study. The ANN consisted of one input layer with N inputs, one hidden layer with q units and one output layer with n outputs. The output of this model can be expressed as [11]:
| (1) |
| (2) |
The GA was first developed by Holland [13] and it was based on the mechanics of natural selection in biological systems. It uses a structure to utilize genetic information for finding new search directions. Major genetic operators that reflect the nature of the evolutionary process are reproduction, crossover and mutation [14].
The GA maintains a population of individuals, whose characteristics are encoded in a fixed-length bit string, modelling the biological genotype [15]. The way these bits represent the phenotype (ontogeny) is at the programmer's direction. As in nature, the genetic material is swapped between the individuals and mutated to produce offspring, with the corresponding changes in phenotypic performance. The crossover operator is an analogue for the recombination of the genetic material as observed in reproduction. Crossover involves splitting the genomic two-parent bit-strings at a given number of locations and then splicing complementary sections of each parent's bit-string in order to form the genotype of the new individual. Crossover occurs with a random probability. The mutation operator simulates natural mutation of DNA. This involves flipping bits in the string in a stochastic manner. Mutation should be fairly infrequent and should be applied following the crossover [14].
The most significant differences among GAs are: i) only the objective function and the corresponding fitness levels influence search directions; ii) GAs use probabilistic transition rules, not deterministic ones; and iii) GAs work on an encoding environment of the parameter set rather than the parameter set itself [15].
3 Database and training
Thermal conductivity at different temperatures and pressures of 41 ionic liquids (400 experimental data points in total) was collected. In this dataset, λ(T,P) properties cover wide ranges: 273–390 K for temperature, 100–20000 kappa for pressure, and 0.10–0.22 W m−1 K−1 for thermal conductivity. This dataset includes cations such as imidazolium, ammonium, phosphonium, pyrrolidinium, and pyridinium. It also includes anions such as halides, sulfonates, tosylates, imides, borates, phosphates, acetates, and amino acids. Fig. 1 shows a general picture of the range of thermal conductivities and ILs considered. These values are of special importance in order to verify that an acceptable range of λ was covered in this study. All data used were chosen from specific databases [16], and corresponded to those claimed by the authors as being experimentally determined [5,6,17–24]. Data available in the literature from theoretical methods, correlations, and extrapolations of any kind were not considered, as well as data whose accuracy was not guaranteed by the authors themselves for any reasons whatsoever (presence of impurities, fluid instability, or problems with the equipment) [25].
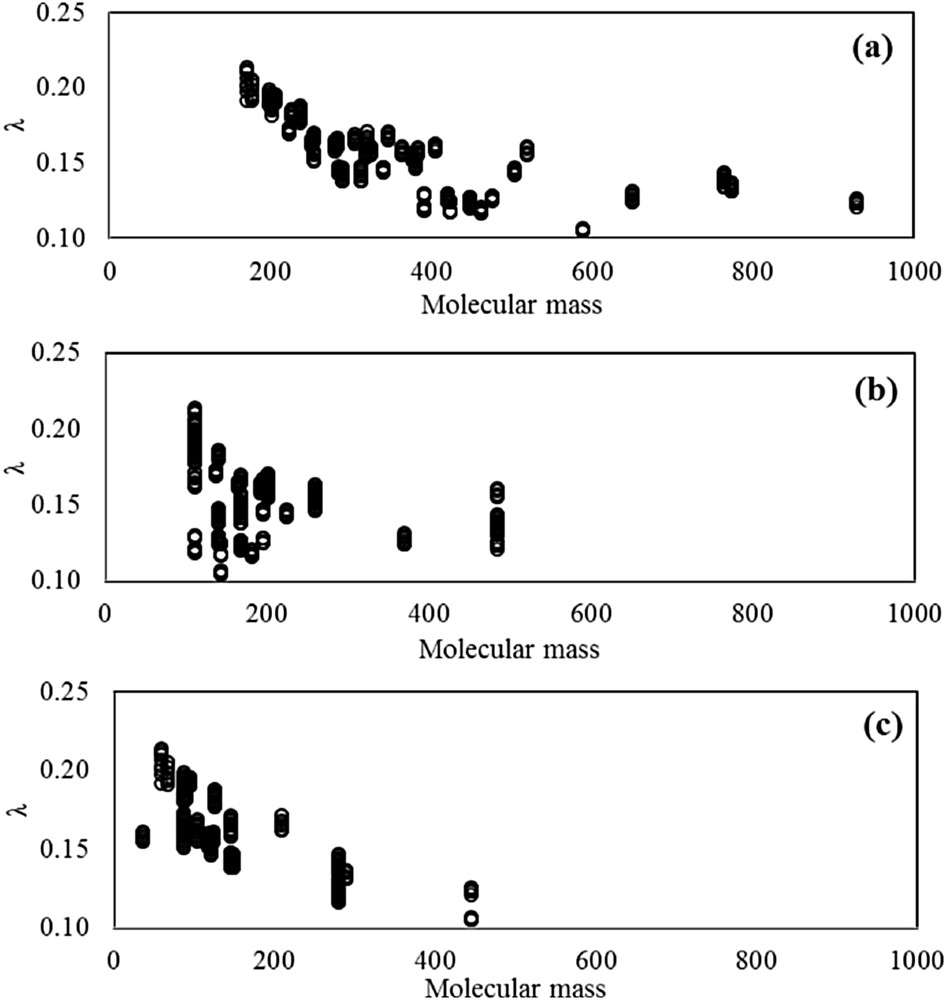
Thermal conductivity as a function of the molecular mass of all ionic liquids used in this study. (a) Total mass distribution, (b) cation distribution, and (c) anion distribution.
Additionally, molecular mass M and molecular structures, represented by the number of well-defined groups forming the molecule, were provided as input parameters in order to characterize the different molecules of ILs. A leave-25%-out cross-validation method was used to estimate the predictive capabilities of the proposed method for entrances such as temperature T, pressure P, molecular mass M, and 28 structural groups. Thus, the whole dataset was divided into a training set with 300 experimental data points, and a prediction set with 100 experimental data points. Table S1 shows the values of experimental thermal conductivity considered in this study (see Supplementary data). Training and prediction sets were selected considering that molecules were decomposed into fragments and all fragments were present with adequate frequency in the training dataset for structural groups. The value associated with the structural group was defined as 0 when the group does not appear in the substance, and as k, when the group appeared k-times in the substance [26]. Table 1 shows all 31 input parameters considered in this study, and contains minimum and maximum input values, and the number of input occurrences in the datasets.
Input considered in the proposed method.
| No. | Input | Xmin | Xmax | No. occurrence | ||
| Training set | Prediction set | Total set | ||||
| 1 | T | 273.15 | 390.00 | 300 | 100 | 400 |
| 2 | P | 100 | 20000 | 300 | 100 | 400 |
| 3 | M | 66.43 | 515.13 | 300 | 100 | 400 |
| 4 | Imidazolium(+) | 0 | 1 | 199 | 42 | 241 |
| 5 | Pyridinium(+) | 0 | 1 | 18 | 9 | 27 |
| 6 | Pyrrolidinium(+) | 0 | 1 | 7 | 9 | 16 |
| 7 | Ammonium(+) | 0 | 1 | 30 | 7 | 37 |
| 8 | Phosphonium(+) | 0 | 1 | 46 | 33 | 79 |
| 9 | –H(+) | 0 | 1 | 217 | 41 | 258 |
| 10 | –(+) | 1 | 4 | 300 | 100 | 400 |
| 11 | –CH2–(+) | 1 | 28 | 300 | 100 | 400 |
| 12 | –(−) | 0 | 4 | 74 | 5 | 79 |
| 13 | –CH2–(−) | 0 | 10 | 56 | 14 | 70 |
| 14 | >CH–(−) [–CH–](−) | 0 | 2 | 51 | 12 | 63 |
| 15 | >C<(−) [>C–](−) | 0 | 1 | 23 | 5 | 28 |
| 16 | –COO–(−) | 0 | 1 | 9 | 0 | 9 |
| 17 | –COOH(−) | 0 | 1 | 42 | 12 | 54 |
| 18 | –OH(−) | 0 | 1 | 30 | 7 | 37 |
| 19 | –O–(−) [–O](−) | 0 | 2 | 65 | 14 | 79 |
| 20 | O(−) | 0 | 1 | 9 | 0 | 9 |
| 21 | –CN(−) | 0 | 3 | 9 | 9 | 18 |
| 22 | >N–(−) | 0 | 1 | 64 | 49 | 113 |
| 23 | –(−) | 0 | 2 | 42 | 26 | 68 |
| 24 | –SO2–(−) | 0 | 2 | 111 | 54 | 165 |
| 25 | –SH(−) | 0 | 1 | 7 | 0 | 7 |
| 26 | –(−) | 0 | 3 | 94 | 40 | 134 |
| 27 | –CF2–(−) | 0 | 3 | 16 | 0 | 16 |
| 28 | –F(−) | 0 | 6 | 104 | 25 | 129 |
| 29 | –Cl(−) | 0 | 1 | 7 | 0 | 7 |
| 30 | –P(−) | 0 | 1 | 59 | 16 | 75 |
| 31 | –B(−) | 0 | 1 | 63 | 9 | 72 |
Subsequently, these input parameters were normalized using the following equation [11]:
| (3) |
The step-by-step for optimum weights calculation using GA is described as follows:
- 1) Initial weights in the ANN are randomly generated (initial population). M-chromosomes are generated randomly in order to serve as the initial population. Each chromosome represents all initial weights and biases in the ANN, which are optimized by the GA.
- 2) Chromosome fitness is evaluated based on the ANN performance. In this case, the fitness function is defined as the root mean square error (RMSE).
- 3) Fitness function value of each individual in the population is evaluated. The lower the RMSE, the higher the probability for chromosomes to be passed down to the next generation. The best individual chromosomes are selected for mating. The selection is repeated until the number of individuals in the mating pool is the same as the number of individuals in the population [26].
- 4) Two individuals are selected randomly from the mating pool as the parent, and random gene selection is used as a crossover point [26]. The transfer of the parent genes to the right of the crossover point generates two new individuals, ending of the single-point crossover [27].
- 5) A mutation operator is applied in order to maintain diversity within the population. Since the initial weights of the ANN could take any values between zero and one, the mutation is conducted by switching random genes. The approximate optimum solutions can be found quickly in order to set up the mutation rate as a parameter to control mutation probability. The mutation rate is a real number between 0 and 1 [28].
- 6) Finally, the best chromosome with the minimum RMSE is chosen and set as the initial weights for the next period in the ANN. The process is repeated until the convergence toward a population of individuals encoding the set of weights that keep the error at a desired level occurs.
Fig. 2 shows a block diagram of the ANN+GA developed in this study. The full methodology was programmed in C++. In a GA, the number of individuals, the crossover operator, the crossover probability, the mutation operator, and the mutation probability summarize the parameters for synchronizing their application in a given problem. An exhaustive trial-and-error procedure was applied for tuning GA parameters. Table 2 shows the selected parameters for the ANN+GA algorithm.
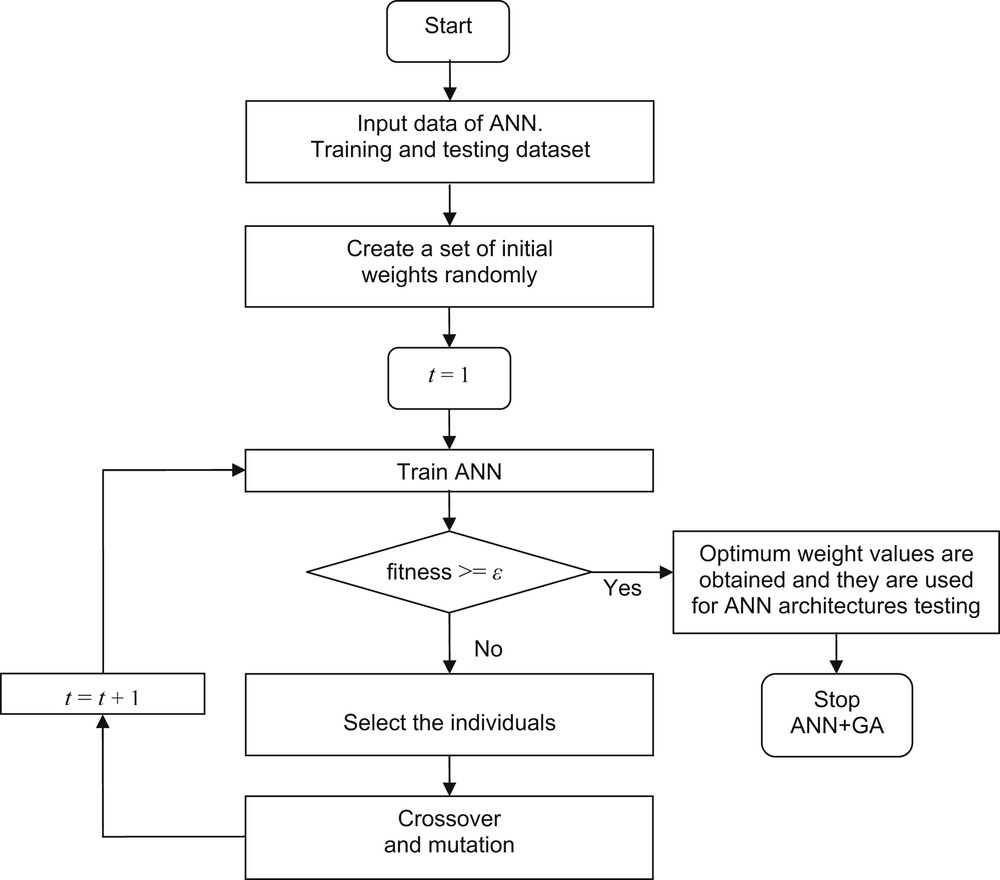
Flow diagram for training of the ANN using GA.
Parameters used in the hybrid ANN+GA technique.
| Section | Parameter | Value |
| ANN | NN-type | feed-forward |
| No. hidden layers | 1 | |
| Transfer function (hidden) | tansig | |
| Transfer function (output) | linear | |
| No. iterations | 1500 | |
| Normalization range | [−1, 1] | |
| Weight range | [−35, 35] | |
| Minimum error | 1e−4 | |
| GA | No. individuals | 100 |
| Crossover operator | two point | |
| Crossover probability | 0.8 | |
| Mutation operator | binary | |
| Mutation probability | 0.02 | |
| Objective function | RMSE |
Using the above methodology, several network architectures were tested to select the most accurate topology. The most basic architecture usually used for this type of application involves a neural network consisting of three layers [29]. The number of hidden neurons should be sufficient for ensuring an adequate representation of the information in the data used for training the network [2]. There is no specific approach for determining the number of neurons of the hidden layer (NHL), but many alternative combinations are possible. Therefore, the optimum number of neurons was determined by systematically adding neurons and evaluating the RMSE of the sets during the learning process [29]. Fig. 3 shows the RMSE found when correlating λ(T,P) as a function of the number of neurons in the hidden layer. As observed in this figure, the optimum number of neurons in the hidden layer is between 4 and 6. The network giving the lowest deviation during training was the one with 31 parameters in the input layer, 5 neurons in the hidden layer, and one neuron in the output layer. The RMSEs of this architecture were 0.00199 during training, and 0.00197 during prediction, respectively.

Root mean square error (RMSE) found in correlating the λ(T,P) of ILs as a function of the number of neurons in the hidden layer (NHL) using ANN+GA. Training step (●) and prediction step (◊).
4 Results and discussion
Once the best architecture was determined, the optimum weights required to carry out the estimate λ(T,P) of ILs were obtained. Table 3 shows the optimum weights for the ANN+GA 31-5-1.
Optimum weights obtained by ANN+GA for model 31-5-1.
| Input | Wij | 1 | 2 | 3 | 4 | 5 |
| T | 1 | −0.78316 | 0.00703 | −0.17960 | 0.26168 | 0.04082 |
| P | 2 | 0.67404 | 0.01776 | −0.28596 | −0.08177 | 0.02026 |
| M | 3 | 0.49567 | −0.42633 | −0.33646 | 0.51141 | −1.92883 |
| Imidazolium(+) | 4 | −0.16750 | −1.16420 | 2.85627 | 1.42302 | 0.53367 |
| Pyridinium(+) | 5 | 2.23931 | 0.57646 | 6.45933 | −0.86621 | 0.11607 |
| Pyrrolidinium(+) | 6 | −0.75567 | 1.19110 | −0.72874 | −1.65053 | −0.62319 |
| Ammonium(+) | 7 | −0.43186 | 0.06006 | 0.10105 | −1.37138 | −0.54707 |
| Phosphonium(+) | 8 | −0.81134 | −0.47999 | −9.26492 | 1.61749 | 2.96438 |
| –H(+) | 9 | −0.93286 | −0.95518 | 9.89140 | 0.15419 | 0.19737 |
| –(+) | 10 | −0.76023 | −0.64633 | −8.34596 | 0.68890 | 1.17553 |
| –CH2–(+) | 11 | 0.72921 | −2.01568 | 34.54003 | 0.97577 | −2.75101 |
| –(−) | 12 | −0.35701 | 0.05285 | −0.08003 | 0.55303 | 0.21510 |
| –CH2–(−) | 13 | 1.66628 | −0.28268 | −0.15251 | −0.10097 | −0.15836 |
| >CH–(−) [–CH–](−) | 14 | −0.32900 | −0.32869 | 0.25780 | −0.75351 | −0.34744 |
| >C<(−) [>C–](−) | 15 | −0.36681 | −0.15418 | −0.07819 | −0.26981 | −0.01303 |
| –COO–(−) | 16 | 0.80487 | 1.64832 | −0.74100 | −1.34253 | 0.33933 |
| –COOH(−) | 17 | 0.34297 | −0.55203 | −0.21594 | 0.93211 | 0.86835 |
| –OH(−) | 18 | −0.04608 | 0.00796 | 0.79831 | 0.09337 | −0.41559 |
| –O–(−) [–O](−) | 19 | −0.91670 | 0.79096 | 0.74844 | 0.23056 | 2.02816 |
| O(−) | 20 | −0.27203 | −0.11996 | 1.04748 | −1.99322 | −0.72868 |
| –CN(−) | 21 | 0.68336 | 1.58632 | −0.89114 | −1.31813 | 0.43514 |
| >N–(−) | 22 | −0.18281 | −1.47621 | −1.27767 | 2.78803 | 1.16030 |
| –(−) | 23 | −1.18164 | 0.24742 | −0.03550 | 0.13463 | −0.52892 |
| –SO2–(−) | 24 | −0.31328 | −2.36592 | −0.25911 | 0.78516 | −1.13372 |
| –SH(−) | 25 | −0.01235 | 0.03879 | −0.27630 | 0.87636 | −0.11776 |
| –(−) | 26 | −1.00636 | −1.26141 | −1.99734 | 0.77169 | 0.57938 |
| –CF2–(−) | 27 | −0.36883 | 1.13458 | −2.08071 | −0.36091 | −1.08332 |
| –F(−) | 28 | 1.22737 | −0.57960 | 0.29477 | 1.41748 | 1.66512 |
| –Cl(−) | 29 | 1.06402 | −0.38947 | 0.04274 | −0.52829 | −0.41591 |
| –P(−) | 30 | −0.60428 | 0.08309 | 2.65385 | −0.69970 | −0.41548 |
| –B(−) | 31 | −0.38003 | −0.20115 | −2.50992 | −0.15801 | −0.06608 |
| W0j | 1.52286 | −0.41596 | 0.31931 | −0.68584 | −2.44430 | |
| Wnj | 0.29242 | −13.79025 | 0.20755 | −13.64070 | 7.61938 | |
| Wn0 | 7.26828 |
The accuracy of the chosen network was verified between the calculated values of λ and the experimental data from the literature, by using the average relative absolute deviation for each data point (|%Δλ|) and for the total set (AARD). These deviations were calculated as follows:
| (4) |
| (5) |
Table S1 shows the results obtained for the correlation set and prediction set, respectively (see, Supplementary data). Table 4 shows the results obtained from the proposed GCM for all different types of ILs; it shows the following ranges of AARD in the prediction of λ(T,P): ammonium < pyridinium < imidazolium < phosphonium < 1%, and pyrrolidinium < 3%. All IL-types presented a maximum error lower than 4%, and all the correlation coefficients R2 are greater than 0.9. Table 5 shows a summary of the deviations of all ILs using the proposed ANN+GA method. The results showed that the ANN+GA can provide an accurate estimation of the thermal conductivity of several ILs: AARD lower than 0.91% for the 300 data points used in the training set, and an AARD lower than 0.84% for the other 100 data points used in the prediction set. The AARD is a little higher than 0.8% for all datasets (400 data points of several ILs), and the deviation is lower than 5% for all data points of the database.
Deviations obtained with the proposed ANN+GA in the estimation of thermal conductivity of ILs.
| IL class | Ndata | Δλ (W m−1 K−1) | ΔT (K) | ΔP (kPa) | AARD | |%Δλ|min | |%Δλ|max | R2 |
| Training set | ||||||||
| Imidazolium | 199 | 0.12–0.22 | 273−390 | 100−20000 | 1.27 | 0.00 | 4.96 | 0.9961 |
| Ammonium | 30 | 0.12–0.17 | 273−353 | 101 | 0.21 | 0.00 | 0.98 | 0.9997 |
| Pyridinium | 18 | 0.16–0.17 | 294−334 | 100−20000 | 0.24 | 0.00 | 0.55 | 0.9934 |
| Phosphonium | 46 | 0.12–0.16 | 282−355 | 101 | 0.19 | 0.00 | 0.64 | 0.9997 |
| Pyrrolidinium | 7 | 0.11–0.13 | 293−353 | 101 | 0.22 | 0.03 | 0.43 | 0.9937 |
| Prediction set | ||||||||
| Imidazolium | 42 | 0.13–0.21 | 273−390 | 100−20000 | 0.68 | 0.03 | 2.22 | 0.9987 |
| Ammonium | 7 | 0.16–0.17 | 298−353 | 101 | 0.09 | 0.00 | 0.16 | 0.9981 |
| Pyridinium | 9 | 0.16–0.17 | 294−334 | 100−20000 | 0.38 | 0.00 | 1.08 | 0.9896 |
| Phosphonium | 33 | 0.13–0.16 | 286−353 | 101 | 0.85 | 0.00 | 3.42 | 0.9878 |
| Pyrrolidinium | 9 | 0.12–0.13 | 293−333 | 101 | 2.67 | 1.79 | 3.53 | 0.9288 |
Summary of deviations in the estimation of thermal conductivity of ILs using the ANN+GA method.
| Statistics | Correlation set | Prediction set | Total set |
| Ndata | 300 | 100 | 400 |
| AARD | 0.91 | 0.84 | 0.89 |
| |%Δλ|min | 0.00 | 0.00 | 0.00 |
| |%Δλ|max | 4.96 | 3.53 | 4.96 |
| |%Δλ|<5% | 300 | 100 | 400 |
| |%Δλ|>5% | 0 | 0 | 0 |
| R2 | 0.9969 | 0.9963 | 0.9967 |
Fig. 4 shows a comparison between experimental (solid line) and calculated (dots) values by the proposed ANN+GA method to estimate λ(T,P). This figure shows a comparison between correlated and experimental values of thermal conductivity. For the training set, the correlation coefficient R2 was 0.9969, and the curve slope (m) was 0.9947 (expected to be 1.0). Also, the figure shows a comparison for the prediction set between calculated and experimental values of λ. In this case, the correlation coefficient R2 is 0.9963 and m (also expected to be 1.0) is 0.9926. For the total set, the correlation coefficient R2 is 0.9967 and m is 0.9945. This figure ratifies the discussion presented above.

Accuracy in the estimation of thermal conductivity of ILs with the proposed ANN+GA method. (○) training set, and (×) prediction set.
Note that for the estimation of λ(T,P = 101.325 kappa), the prediction set presents a very low deviation (AARD = 0.88%) with an |%Δλ|max of 3.53%. In particular, the dataset of 1-butyl-1-methylpyrrolidinium bis[(trifluoromethyl)sulfonyl]imide [20] showed a highest AARD of 2.92%. In addition, the prediction set also showed a very low AARD of 0.66% with a |%Δλ|max of 2.22% for the estimation of the thermal conductivity at different temperatures and pressures λ(T,P). In this case, the prediction set presents an AARD of 0.40% for pressures higher than the atmospheric pressure (P > 101.325 kappa).
Recently a number of methods have been proposed for the estimation of thermal conductivity of ILs [30] (see, the Introduction section). It is worth pointing out that all these methods obtained their results from different databases with different correlation and prediction sets (or training and prediction sets), and based on different methodologies and the results cannot be compared directly with one another. However, a comparison can be made for the selected datasets of common ILs for all methods. Table 6 shows a comparison between the proposed neural network method for the λ estimation of ILs and other methods reported in the literature such as group contribution methods (GCM), generalized correlations, and quantitative structure–property relationships (QSPR). This table contains 20 datasets of ILs at atmospheric pressure and several temperatures. Only four methods can be completely compared based on these results. Albert−Müller's GCM [8] showed an AARD of 2.19, Wu's method [9] presented an AARD of 1.89, Lazzús's QSPR model [30] resulted in an AARD of 2.09, and the proposed neural network method showed an AARD of 1.35. On the one hand, Gardas–Coutinho's GCM [7] does not perform for any ILs due to the group division principle, and it cannot be extended to others ILs [30]. On the other hand, Wu's method [9] and Shojaee's method [3] depend on the knowledge of other properties of ILs. Therefore, the proposed neural network method presented better accuracy and more advantages than other methods to predict λ of ILs at atmospheric pressure and different temperatures.
Comparison between the proposed neural network method and other methods reported in the literature for the λ(T) estimation of ILs.
| Ionic liquid | ΔT (K) | Ndata | Gardas−Coutinho GCM [7] AARD | Albert−Müller GCM [8] AARD | Wu et al. Correlation [9] AARD | Shojaee et al. Correlation [3] AARD | Lazzús QSPR [30] AARD | This work ANN+GA | Ref. |
| [C2mim][NTf2] | 273.15–353.15 | 9 | 6.41 | 4.02 | 5.84 | 6.54 | 3.69 | 3.83 | [6] |
| [C2mim][EtSO4] | 293.00–353.00 | 7 | 0.15 | 2.00 | 1.30 | 9.34 | 3.50 | 0.87 | [20] |
| 273.15–353.15 | 9 | 2.53 | 1.10 | 11.16 | 0.89 | 0.74 | [6] | ||
| [C2mim][CH3COO] | 273.17–353.15 | 9 | – | 0.85 | 0.86 | – | 3.32 | 0.25 | [6] |
| [C2mim][DCA] | 273.17–353.15 | 9 | – | 1.76 | 0.58 | 14.72 | 0.80 | 0.31 | [6] |
| [C2mim][C(CN)3] | 273.17–353.15 | 9 | – | 0.33 | 0.74 | – | 1.52 | 0.27 | [6] |
| [C4mim][OTf] | 293.00–353.00 | 7 | 0.15 | 1.71 | 0.37 | 1.92 | 0.55 | 1.68 | [20] |
| 293.00–353.00 | 7 | 3.51 | 3.09 | 3.82 | 3.00 | 1.74 | [21] | ||
| [C4mim][NTf2] | 293.00–353.00 | 7 | 1.26 | 2.65 | 1.00 | 3.29 | 3.21 | 2.38 | [20] |
| [C4mim][PF6] | 293.00–353.00 | 7 | 0.98 | 0.88 | 1.55 | 2.40 | 0.96 | 0.26 | [21] |
| 294.90–335.10 | 3 | 0.69 | 1.40 | – | 1.01 | 0.34 | [5] | ||
| [C6mim][NTf2] | 293.00–353.00 | 7 | 1.40 | 1.69 | 1.97 | 3.66 | 2.65 | 3.03 | [20] |
| 273.15–353.15 | 9 | 5.26 | 1.88 | 5.34 | 1.00 | 0.78 | [6] | ||
| [C6mim][BF4] | 293.00–353.00 | 7 | 23.09 | 4.55 | 1.20 | 0.76 | 0.72 | 2.03 | [21] |
| [C6mim][PF6] | 293.00–353.00 | 7 | 4.32 | 2.07 | 1.51 | 2.27 | 4.00 | 1.21 | [21] |
| 294.10–335.20 | 3 | 0.95 | 1.78 | – | 1.35 | 0.95 | [5] | ||
| [C8mim][PF6] | 295.10–335.20 | 3 | 1.20 | 2.07 | 3.02 | – | 3.15 | 0.49 | [5] |
| [C8mim][NTf2] | 293.00–353.00 | 7 | 1.09 | 3.41 | 3.01 | – | 1.01 | 0.46 | [20] |
| [C4mpyrr][NTf2] | 293.00–323.00 | 4 | 0.19 | 2.65 | 0.77 | 6.05 | 2.98 | 2.92 | [20] |
| 293.00–333.00 | 5 | 5.84 | 4.76 | 10.91 | 2.52 | 2.47 | [21] | ||
| AARD | 3.47 | 2.19 | 1.89 | 5.87 | 2.09 | 1.35 |
In other comparison, using Shojaee's method [3] at different pressures (100−20000 kappa) resulted in an AARD of 3.47% for three ILs, while the proposed neural network method showed an AARD of 0.64%. Table 7 shows the ILs and ranges of temperatures and pressures used in this comparison. Table 7 clearly shows that the proposed neural network method offered better accuracy and more advantages in the λ estimation of ILs at several temperatures and pressures only by knowing the molecular structure of IL.
Comparison between the proposed neural network method and other method reported in the literature for the λ(T,P) estimation of ILs.
| Ionic liquid | ΔT (K) | ΔP (kPa) | Ndata | Shojaee et al. Correlation [3] AARD | This work ANN+GA AARD | Ref. |
| [C4mim][PF6] | 294.90–335.10 | 100–20000 | 9 | 3.16 | 0.47 | [5] |
| [C6mim][PF6] | 294.10–335.20 | 100–20000 | 9 | 2.97 | 0.95 | [5] |
| [C8mim][PF6] | 294.10–335.20 | 100–20000 | 9 | 4.29 | 0.49 | [5] |
| AARD | 3.47 | 0.64 |
In addition to these results, a comparison was made with a neural network with standard back-propagation (BPNN), and similar architecture (31-5-1) and database. The BPNN showed an AARD of 2.5%, and a |%Δλ|max higher than 15%. Fig. 5 shows a |%Δλ| found during the prediction of thermal conductivity of ILs using the BPNN versus a |%Δλ| obtained using the proposed ANN+GA method. In other applications relative to BPNN, Hezave et al. [12] presented a neural network model to predict thermal conductivity of ionic liquids. In Hezave's neural network model a total of 209 data points from 21 different ionic liquids were used to train and test the BPNN, and the optimum architecture was determined to be 4-13-1, with input parameters such as temperature T, pressure P, molecular weight MW, and melting point temperature Tm. A considerable disadvantage of Hezave's neural network model is the use of melting point temperature of ILs. Note that, for organic compounds, Pérez Ponce et al. [31] showed an AARD higher than 7.5% for several methods reported during years 1987–2006; additionally, they presented an AARD for three commercial softwares for predicting Tm with an AARD higher than 12% and maximum deviations higher than 45%. For ILs, Huo et al. [32] presented a group contribution method (GCM) for estimating the melting point of imidazolium-ILs with an AARD of 5.9% and maximum deviations higher than 32%. Coutinho et al. [33] presented a critical review on predictive methods for the estimation of thermophysical properties of ILs, with R2 from 0.6 to 0.9 for the prediction of Tm. Thus, the reliability of the input data is never established, making interpretation of deviations between the Hezave's neural network model and experimental data of thermal conductivity of ILs impossible to be made. In contrast, low deviations from the proposed ANN+GA method (an AARD a little higher than 0.8% and a |%Δλ|max below than 5%) indicate that it can estimate λ(T,P) of ILs with low deviations and can be relied on an accuracy of 99%. All these results represent a big increase in accuracy for predicting this important property, and show that the application of the proposed ANN+GA method was crucial. An important observation that is worth pointing out is the influential effects of the structural groups in the correlation and prediction of the thermal conductivity. Considering that the big differences in the chemical structure and physical properties of the ILs used in the study place additional difficulties that the proposed ANN+GA method was able to handle.

Deviations found in the prediction of λ(T,P) of ILs using ANN+GA (○) and BPNN (Ж).
The incorporation of a GA for the optimization of the neural network weights has positive effects on architecture reducing the number of neurons in the hidden layer while controlling the selection of network connection weightings in a wide numeric range (see, Table 2). Note that, traditional optimization techniques such as the back-propagation learning algorithm can also determine the number of network parameters, such as network connection weightings; however, traditional optimization techniques are not able to control the network parameter optimizations. In contrast, the GA was able to solve this problem.
5 Conclusions
In this study, the thermal conductivity of several ILs at different temperatures and pressures was correlated and estimated using an artificial neural network optimized with a genetic algorithm in order to update the weights of the network.
Based on the results and discussion presented in this study, the following conclusions are obtained: (i) the great differences in the chemical structure, and the physical properties of the ionic liquids considered in the study impose additional difficulties to the problems that the proposed ANN+GA method has been able to handle; (ii) the results show that the ANN+GA method can estimate the thermal conductivity of ionic liquids at different temperatures and pressures with low deviations. The consistency of the method has been checked using experimental values of thermal conductivity and comparing them with the calculated values by the proposed method; (iii) the values calculated using the proposed model are believed to be accurate enough for engineering calculations, for generalized correlations and for equations of state methods, among other uses; and (iv) the incorporation of a GA for the optimization of the neural network weights has positive effects on architecture reducing the number of neurons in the hidden layer while controlling the selection of network connection weightings in a wide numeric range.
Acknowledgements
The author thanks the Direction of Research of the University of La Serena (DIULS), through the research project PT13144. Special thanks go to the Department of Physics of the University of La Serena (DFULS) for the special support that made possible the preparation of this paper.