

1 Introduction
Linear transformation of spatially correlated variables into uncorrelated factors has been one of the most challenging issues in mining engineering and earth sciences. In this direction, several methods have been introduced by researchers. Xie et al. (1995) and Tercan (1999) used simultaneous diagonalisation in finding approximately uncorrelated factors at several lag distances by simultaneously diagonalising a set of variogram matrices. Switzer and Green (1984) developed the method of Minimum/Maximum Autocorrelation Factors (MAF) for the objective of separating signals from noise in multivariate imagery observations. The method is first introduced to geostatistical community by Desbarats and Dimitrakopoulos (2000) in the context of multivariate geostatistical simulation of pore-size distributions.
Fonseca and Dimitrakopoulos (2003) used MAF method for assessing risks in grade-tonnage curves in a complex copper deposit. Boucher and Dimitrakopoulos (2009) presented a method for the conditional block simulation of a non-Gaussian vector random field. They, first, orthogonalised a vector random function with MAF method and then used LU simulation to generate possible realizations. Rondon (2011) discussed the joint simulation of spatially cross-correlated variables using MAF factors in detail and gave some examples.
MAF is basically a two-stage principal component analysis applied to variance–covariance matrices at short and long lag distances. Goovaerts (1993) proves that in the presence of a two-structure linear model of co-regionalization (2SLMC), the factors are spatially uncorrelated. But the assumption of a 2SLMC is not reasonable for most of real data sets and also an extension of MAF to more than two distinct structure matrices is not possible (Vargas-Guzmán and Dimitrakopoulos, 2003). In the case where fitting a 2SLMC is not possible, a data-driven version of MAF method can be used (Desbarats and Dimitrakopoulos, 2000; Tercan, 1999; Sohrabian and Ozcelik, 2012a). In this approach, the variance–covariance matrices are calculated directly from the data set.
There are also some studies that use the independency property of the generated factors. For example, Sohrabian and Ozcelik (2012b) introduce Independent Component Analysis (ICA) to transform spatially correlated attributes of an andesite quarry into independent factors. Then they estimated each factor independently and back-transformed the results into the real data space to determine exploitable blocks. Tercan and Sohrabian (2013) used independent component analysis in joint simulation of some quality attributes of a lignite deposit.
Goovaerts (1993) proves that in the general case, it is impossible to find factors that are exactly uncorrelated at all lag distances. When spatially uncorrelated factors cannot be produced, one looks for algorithms that produce approximately uncorrelated factors. For that, Mueller and Ferreira (2012) used Uniformly Weighted Exhaustive Diagonalization with Gauss iterations (U-WEDGE), introduced by Tichavsky and Yeredor (2009), for joint simulation of a multivariate data set from an iron deposit. In their case study, Mueller and Ferreira (2012) show that the U-WEDGE algorithm performs better than MAF.
In the present study, Minimum Spatial Cross-Correlation (MSC) method is introduced for generating approximately uncorrelated factors. It aims to minimise cross-variance matrices at different lag distances using the gradient descent algorithm. In this method the de-correlation problem is reduced to the solution of a sequence of 2 by 2 problems. Against other blind source separation algorithms such as U-WEDGE and ICA which generally work in high-dimensional spaces and try to solve the problem by choosing N × N initial matrices the MSC method is more convenient. In addition, ICA and U-WEDGE algorithms are sensitive to the choice of the initial matrices so that several applications of these algorithms do not converge to the same result (Hyvarinen et al., 2001). But, the MSC method approximately converges to the same result and this can be considered as an advantage over methods that directly solve N × N optimization problems.
The outline of the paper is as follows: the second section describes multivariate random field model. The third section explains the theory of MSC. The method is presented in 2D and then is generalized into an N-dimensional space. In the fourth section the method is applied to joint simulation of multivariate data obtained from an andesite quarry and the efficiency of the method in generating spatially orthogonalised factors is measured and compared to that of MAF method. Then MSC and MAF factors are used to simulate some attributes of a marble quarry. The last section includes the conclusions.
2 The multivariate random field
Let be an N-dimensional stationary random field with zero mean and unit variance. In this multivariate case, the variogram matrix is given by
| (1) |
The variogram matrix depends only on the lag distance h, assuming that correlations vanish as . In the presence of spatial cross-correlation, each variable should be simulated by considering the cross-correlations. In such cases, the traditional method is co-simulation, but it is impractical and time consuming due to difficulties arising from the fitting of a valid model of coregionalisation and the solving of large cokriging systems (Goovaerts, 1993). To ease multivariate simulation, Z(u) can be transformed into spatially uncorrelated factors F(u) in such way that
| (2) |
3 MSC Method
Researchers have proposed various methods for generating spatially orthogonal factors. Some criteria have also been introduced to measure how well these methods orthogonalise the variogram matrices at different lag distances. For example, Tercan (1999) proposed the following measure:
| (3) |
While developing our method in deriving spatially uncorrelated factors, we will consider Eq. 3, proving that is constant (see Appendix A for a proof). Therefore it suffices to minimize the sum of values at various lag distances. In the following section, a simple method based on the gradient descent algorithm is presented for iteratively minimizing the value.
| (4) |
In Eq. 4, l denotes the number of lags that are considered in the calculations. The number of lags depends on the smallest distance that the experimental variograms are calculated and also on the maximum range of the auto or cross-variograms of variables. The number of lags can be chosen by dividing the maximum range of variograms by the average sampling distance.
Another issue is unequal sampling, which affects the calculation of cross-variograms. In case of partial heterotopy where some variables share some sample locations, it is advisable to infer the cross-variogram model on the basis of the isotopic subset of the data (Wackernagel, 2003). This is known as complete-case analysis. The method suggested in this study works for complete case data. However, this approach reduces the sample size and results in loss of information due to discarding incomplete samples. This can cause loss of precision and potentially bias when the complete cases are not a random sample of the population (Little and Rubin, 2002). Instead, imputation methods can be used to supply missing observations to complete a data set. The approaches to imputing vary from the simplest form, taking an average of nearby simple values, to complicated ones, for example multiple imputation. More detail on imputing can be found in Little and Rubin (2002).
In minimization problems, the derivatives of functions are used widely. It is known that the absolute value of functions may not be differentiable at some points in their domains. We work with whitened data with cross-variograms lying between–1 and 1, so that can be replaced by without changing in the directions that minimize Eq. 4. Therefore, the objective function takes the following form:
| (5) |
In practice, to minimize Eq. 5, we would start from some vector w, compute the direction in which the value of new factors F=ZW is growing most rapidly, based on the available samples of spatially correlated variables and then move the vector w in the opposite direction.
3.1 Gradient descent algorithm
This section includes a short explanation of the algorithm. Let f(x) with , be a differentiable scalar field. We want to find its minimum. Then the gradient at location x represents a direction where the function increases and is usually called the steepest descent direction. For finding the minimum of f(x), the gradient descent algorithm starts from an initial point x1, then iteratively takes a step along the steepest descent direction, optionally scaled by a step length, until convergence. Gradient descent is popular for very large-scale optimization problems because it is easy to implement and its iterations are cheap.
The algorithm typically converges to a local minimum, but in the presence of only one saddle point it gives a global minimum. If is a starting point, a step length, a tolerance value or constraint, and f(x) an objective function, then the algorithm can be given as follows:
- 1. start iteration
- 2.
- 3. if f(xt) > f(xt-1) then
- 4. if go to step 2
- 5. end
The objective function of our optimization problem is presented in Eq. 5. In this study, an N × N optimization problem will be replaced by a set of two-dimensional problems, so that, at first, we assume the simplest case of two spatially cross-correlated variables. In Eq. 5, the aim is to find a transformation matrix, W, which gives factors with the lowest spatial cross-correlation. The columns of matrix W, denoted by w, give the directions of the factors that we are looking for. To restrict the number of possible w vectors, a whitening process is performed by using principal component analysis therefore the mean and variance of Z become 0 and 1, respectively. The optimization problem is now reduced to a unit circle and we search for a vector w so that the linear combination ZW has a minimum value. For this two-dimensional case, the point on the unit sphere can be parameterized by the angle that the corresponding vector w makes with the horizontal axis. The function is periodic, with a period equal to rad, and the vector w gives the direction of the first factor. The direction of the second factor is perpendicular to that of the first one.
3.2 Minimizing value between two variables using gradient descent algorithm
Assume that the experimental semivariogram matrix for hi is given as follows:
| (6) |
The objective is to find a 2 × 2 transformation matrix W
| (7) |
| (8) |
| (9) |
Eq. 9 has only one parameter and we can use gradient descent (Battiti, 1992; Hyvarinen et al., 2001) to minimize it iteratively. For minimization of , we start from an initial point, , compute the gradient of at this point and move in the direction of negative gradient or the steepest descent by suitable distance. Repeat the same procedure at the new point, and so on. The derivative of with respect to is:
| (10) |
3.3 Applying the algorithm to an N–dimensional case
Blind source separation methods such as independent component algorithms use N × N matrices and their first- and second-order derivatives, which are difficult to manage (Sohrabian and Ozcelik, 2012b; Tercan and Sohrabian, 2013). On the other hand, the new developed algorithm is simple as you only need to solve one-dimensional problems, while the actual matrices are still N by N. The N × N space is divided into two-dimensional spaces and the previous algorithm is run for each 2-D space where the related axes are rotated to renew the factors, and the algorithm is set to work for the remaining 2-D spaces. In case of N × N space, the problem is simplified to the calculation of rotation angles. Then, the final transformation matrix is calculated as follows:
| (11) |
This technique is applied to an andesite deposit containing four variables to illustrate how decreases after each 2-D rotation (Fig. 1). Considering the maximum range of auto and cross-variograms and the average distance of sample locations, we chose five variogram matrices at distances 20 m, 40 m, 60 m, 80 m and 100 m. The magnitude of derivative obtained from iteration was too small and therefore the initial value for was taken to be 5000. The value of was divided by 2 for five times as getting closer to the minimum point. Fig. 1 shows that, after each 2-dimensional transformation and renewing factors, the value decreases gradually from the whitened components to the MSC factors.
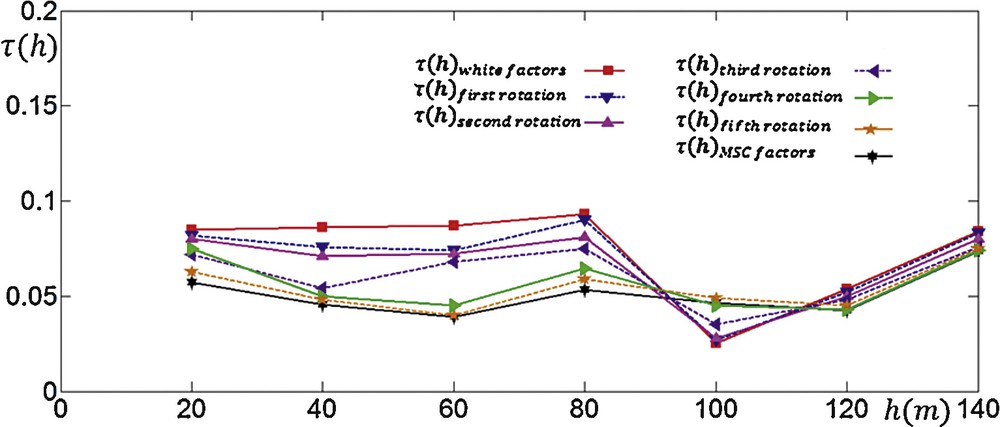
(Colour online) Decrease in value as iteration progresses in 2-D spaces. For example shows values of factors obtained after first rotation in 2-D space of first and second factors.
4 Case study
The study area is an andesite quarry located in the Çubuk district, 60 km north-east of Ankara, Turkey. In the area, a total of 108 samples at 20-m regular intervals were collected and the samples were tested for Uniaxial Compressive Strength (UCS), Tensile Strength (TS), Elasticity Modulus (EM) and Los Angeles abrasion for 500 revolutions (Los 500) according to Turkish standards (TSE, 1987). The mechanical properties are tested on core samples with the same size. Therefore the variables considered in the study can be said to be additive. Among these variables, EM and TS are positively skewed and Los 500 is strongly negatively skewed. The UCS is the only attribute with a symmetric distribution (not shown here). Table 1 gives summary statistics for each variable and correlation coefficients between them. Correlation coefficients are relatively high with absolute values more than 0.8. The highest correlation coefficient occurs between Los 500 and TS and then UCS and TS.
Summary statistics and correlation coefficient matrix of variables.
| Variable | Minimum | Mean | Maximum | Skewness | Variance |
| EM | 7.80 | 14.20 | 28.70 | 1.09 | 23.16 |
| TS | 5.09 | 8.76 | 13.45 | 0.32 | 5.30 |
| UCS | 20.00 | 63.35 | 105.00 | 0.00 | 375.07 |
| Los 500 | 11.20 | 14.31 | 16.20 | –0.63 | 1.48 |
| Correlation coefficient matrix of variables | |||||
| EM | TS | UCS | Los 500 | ||
| EM | 1 | 0.82 | 0.80 | –0.82 | |
| TS | 0.82 | 1 | 0.94 | –0.94 | |
| UCS | 0.80 | 0.94 | 1 | –0.88 | |
| Los 500 | –0.82 | –0.94 | –0.88 | 1 |
4.1 Transformations
MSC method was run by considering the sum of cross-variograms at five lag distances. Lag distance and lag tolerance were chosen as 20 m and 10 m, respectively. Prior to running MSC method, a whitening process was performed by using PCA. Whitening process and MSC transformation were done using Twhitening and AMSC matrices, respectively:
For MAF approach, auto and cross-variograms of standardised variables were calculated at two lag distances equal to 28 and 100 m. Then, the overall transformation matrix from original data to MAF factors was obtained:
The MSC and MAF factors were produced by multiplying the transforming matrices by the data matrix. Fig. 2 shows the cross-variograms of factors obtained by these methods. Fig. 2 also compares the efficiency of orthogonalization methods using measure. It is obvious that the cross-variograms of the MSC factors are in a tighter interval than those of MAF factors. Considering values, the MSC method seems to be more efficient than MAF method in producing orthogonalised factors at most lag distances but 100 m.
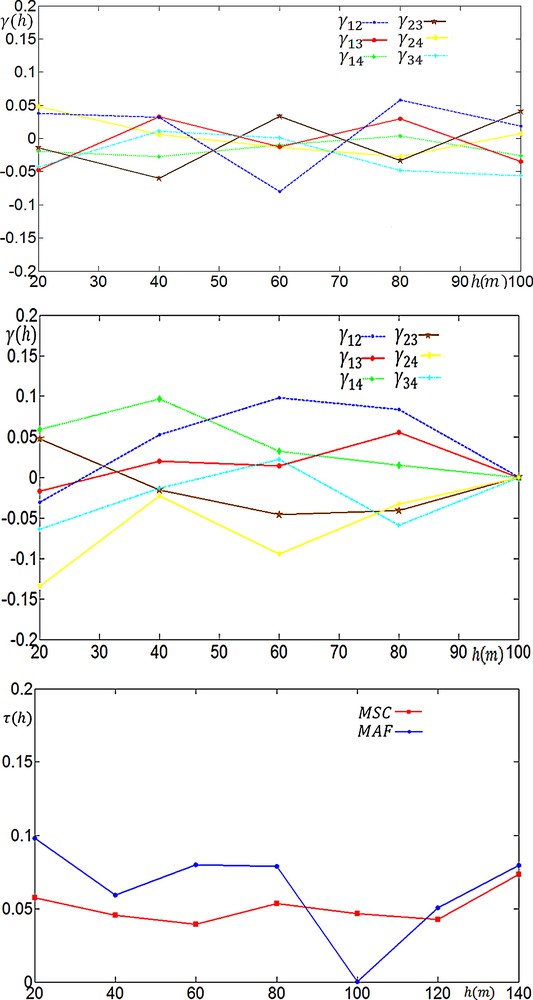
(Colour online) Cross-variograms of factors obtained by MSC (top left) and MAF (top right) methods and their orthogonalization efficiency plot (bottom).
4.2 Simulations
By running the Jarque–Bera test of normality at the 5% significance level, it can be said that all factors but MAF3 have a normal distribution. Experimental variograms of MSC and MAF factors are calculated and shown together with the fitted models and model parameters (Fig. 3). The model variograms of all factors consist of pure nugget and of one spherical scheme. All factors have isotropic variogram models except the third MSC factor. For each factor, 100 realizations were generated separately by considering the direct sequential simulation algorithm introduced by Oz et al., 2003. Most factors show normal distribution so that they can be simulated by the direct sequential simulation method without any normal scores transformation. The simulated realizations were then back-transformed into the real data space. For simulation, a 5 × 5 regular grid containing 1911 nodes was used.
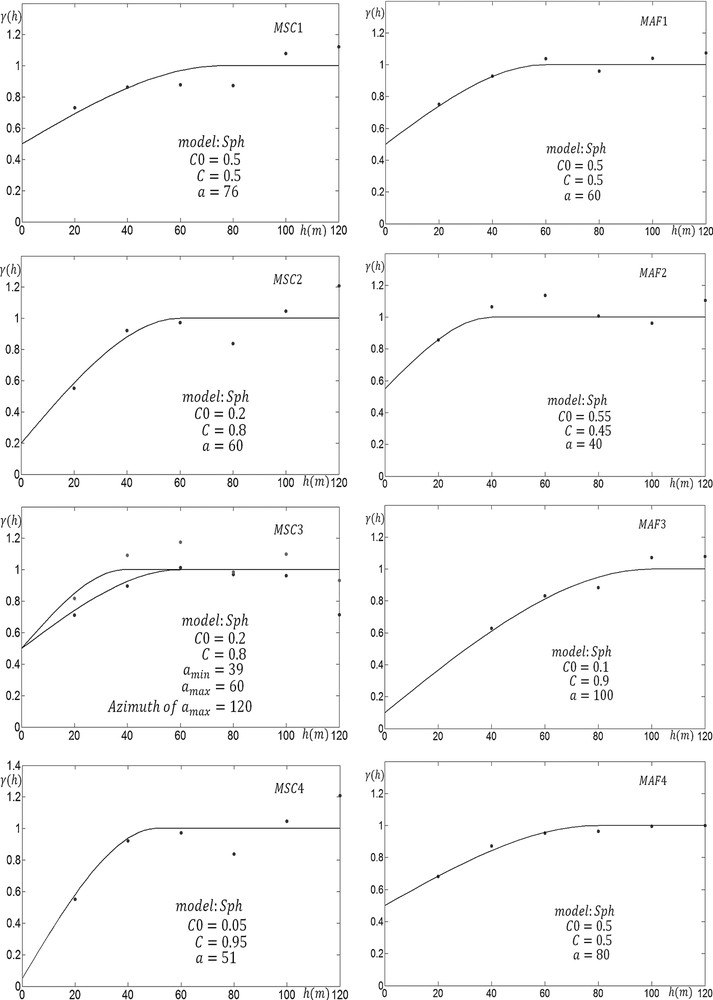
(Colour online) Auto-variograms of MSC and MAF factors together with the fitted models (black solid line) and model parameters.
4.3 Comparison of the simulation results
To compare MSC and MAF simulations, some tests were carried out. For this purpose, the following criteria are considered: reproduction of summary statistics, cumulative histograms, correlation coefficients and auto/cross-variograms.
The mean and variance values of 100 realizations obtained from both simulation methods are shown in Fig. 4. Practically, there is no noticeable difference between mean values of MSC and MAF realizations. Compared to the variance of actual values, the variance of MAF realizations is high, while the variance of MSC realizations is low. Fig. 5 shows the cumulative histograms of realizations obtained from MSC and MAF simulations. It can be said that reproduction of CDF is acceptable for both methods.
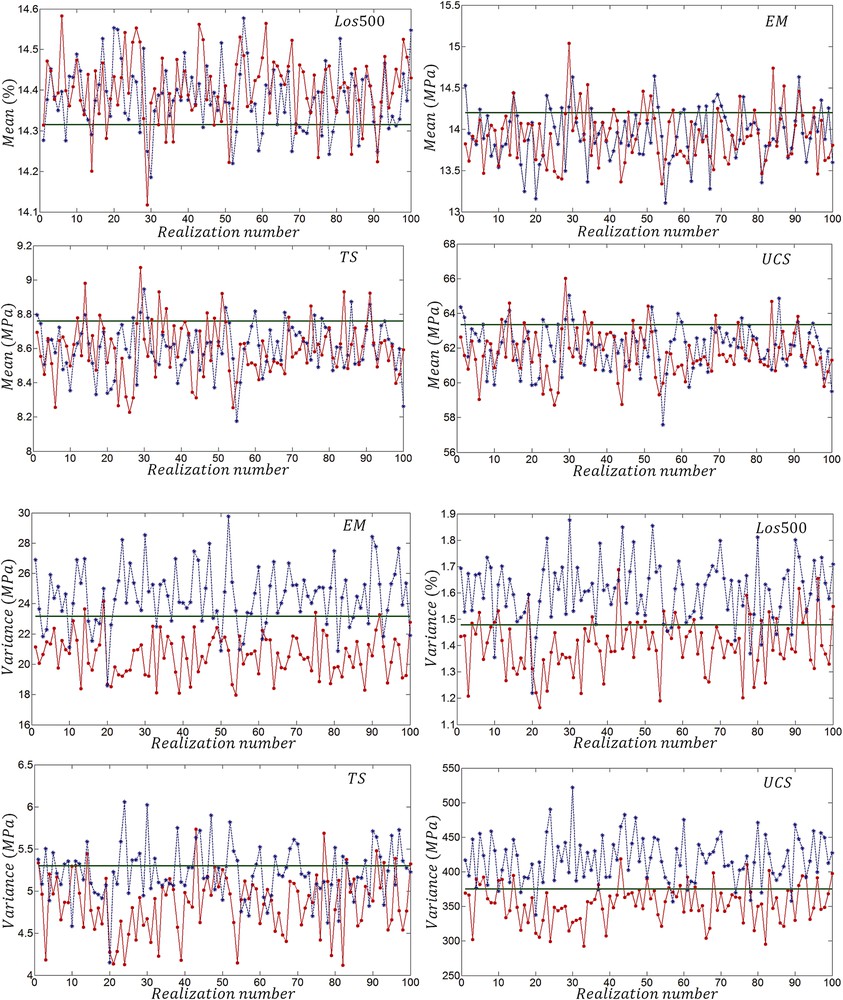
(Colour online) Comparison of the mean and variance of variables (green straight line) with simulated realizations obtained using MSC () and MAF () factors.
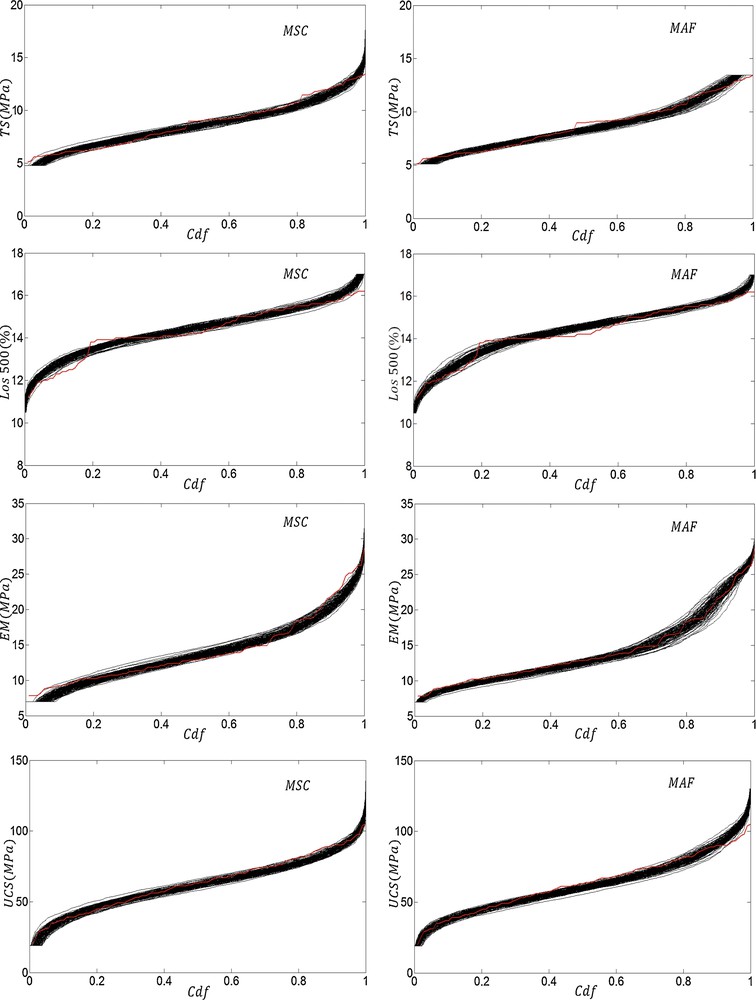
(Colour online) Cumulative distribution functions for one hundred realizations for each attribute obtained using the MSC and MAF simulation methods. Solid red lines demonstrate the cumulative distribution function of the original variables.
The next test consists in comparing the correlation coefficients of simulations to those of real data. The reproduction of sample correlations is perfect for MSC simulations and reasonable for MAF simulations (Fig. 6). In general, for each attribute, the mean value of correlation coefficients of MSC simulations is closer to the sample correlation coefficient.
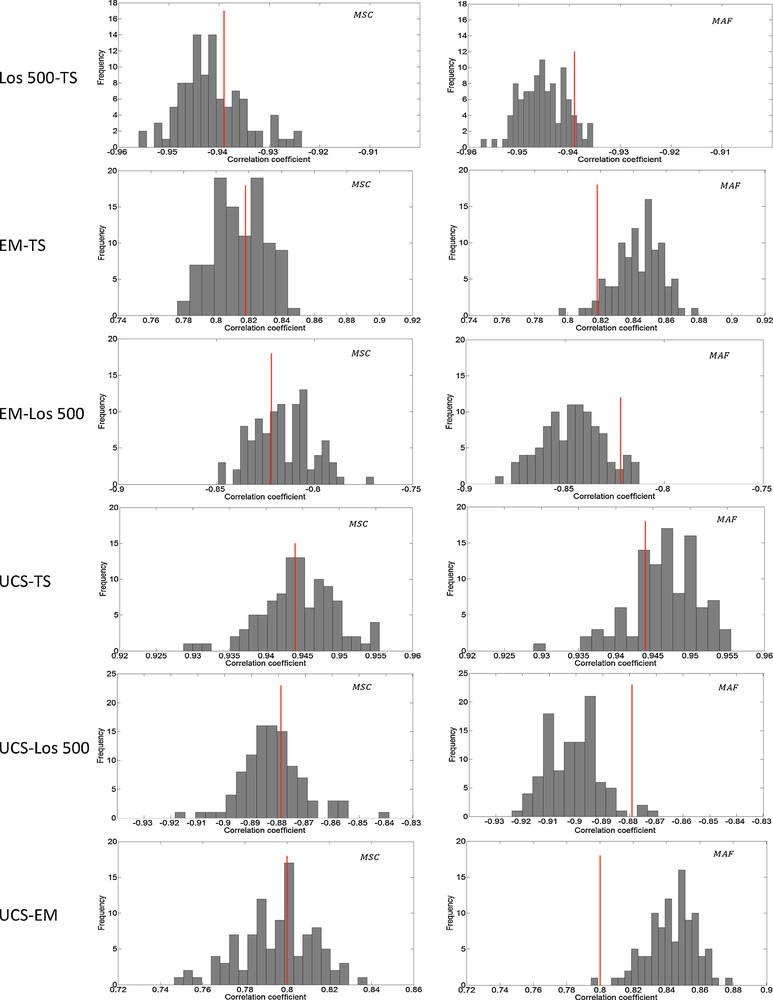
Histogram of simulation correlation coefficients together with aimed values (red solid line) (For interpretation of the references to color in this figure, the reader is referred to the web version of this article).
The experimental auto and cross-variograms of 100 realizations for both methods are shown in Fig. 7. The experimental variograms for MSC simulation change in a narrow interval compared to the experimental variograms of MAF simulation. This is an expected result when we consider the variances of the realizations for both methods as shown in Fig. 4. In average, the sample variograms are well produced by MSC over MAF. In addition, MSC reproduces short-range variability better than MAF.
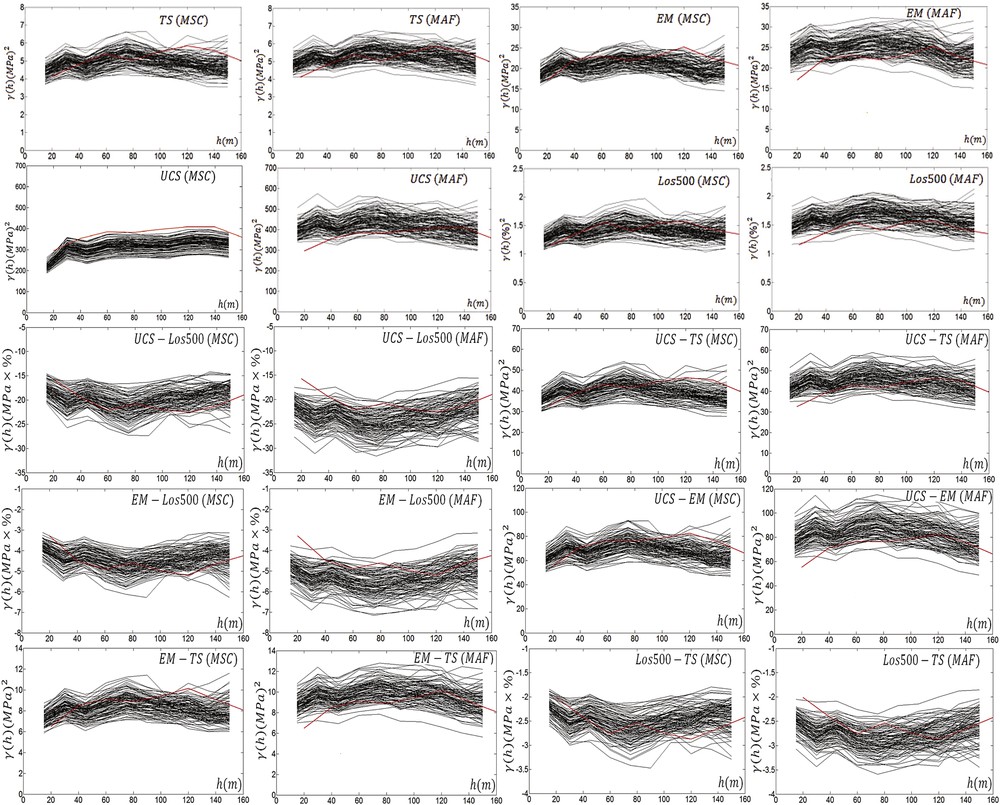
Auto and cross-variograms (black solid lines) of simulation results together with target variograms (red solid line). (For interpretation of the references to colour in this figure, the reader is referred to the web version of this article).
5 Conclusions
In this paper, a novel method is presented for spatially orthogonalization of multivariate data. Then, the results of joint simulations obtained by this method are compared to MAF simulations. MSC simulation method shows better performance over MAF. At most lag distances, the factors generated by MSC method have lower values than MAF factors so that they are spatially more uncorrelated than factors obtained by MAF method.
The case study shows that the reproduction of target statistics for MSC and MAF simulations is acceptable. The methods produce practically similar average values. MSC produces the simulated realizations with low variances, while MAF realizations show high variances. The CDF reconstruction of simulated attributes is acceptable for both methods. However, the reproduction of target correlation coefficients is good for MSC method and reasonable for MAF simulation. Also, MSC simulations reproduce auto and cross-variograms better than MAF simulations. In particular, the short-range variability is well produced in MSC.
Minimization of cross-variograms is not the only criterion to use. Some other criteria can also be defined. For example, a new measure of spatial independency rather than spatial uncorrelatedness can be introduced. In addition, the MSC criterion based on the minimization of cross-variograms at different distances assumes that each distance is equally weighted. One can however consider different weights for each distance. MSC algorithm cannot handle non-linear correlations among variables since it uses linear transformations. Therefore, the method should be developed further in order to consider non-linear correlations.
Acknowledgement
This study is supported by the Scientific and Technical Research Council of Turkey (TUBITAK) under Grant 111M218.
Appendix A
Proof: Suppose that the number of variables is equal to 2. This can be easily generalized to N. is constant:
, for the whitened data and also
The derivative of with respect to can be given as follows:
The expansion of in terms of is:
The derivative of with respect to is as follows:
Then